
VGG-16 è un’architettura di rete neurale progettata da Visual Geometry Group, il dipartimento di scienze ingegneristiche dell’Università di Oxford, con 13 convolutional layers e 3 fully connected layers per task di classification e detection (classificazione e identificazione)
Sempre presente poi la ReLU ereditata da AlexNet.
Dunque, dopo aver studiato la struttura della LeNet-5 e l’AlexNet vediamo ora quella della VGG-16 nel nostro percorso sulle CNN Network.
Un Deep Learning Engineer mastica backpropagation e cost function a colazione, progettando CNN Networks a colpo d’occhio.
Questa frase, ormai un mantra, ci introduce alla scoperta delle meraviglie nascoste di questi sistemi.
Procediamo.
VGG-16 CNN Network
L’immagine d’input ha dimensioni 224x224x3, permettendoci anche in questo caso di processare immagini a colori (tre canali, RGB).
Come avrai modo di notare a breve, tra le particolarità di questa architettura troviamo l’impiego di filtri convoluzionali (ricettivi) molto piccoli. (small receptive field)
Dimensione? 3×3, la minore per catturare la nozione di destra / sinistra, sopra/sotto centro.
Ce ne sono anche altri da 2×2, e addirittura 1×1 che può essere visto come trasformazione lineare dei canali d’input, a cui è associata una non-linear transformation.
Padding e stride sono tarati in modo tale che la risoluzione spaziale rimanga costante dopo l’applicazione del filtro.
Come fatto per le architetture passate, ti esorto anche questa volta ad accostare l’immagine sottostante alla descrizione testuale della struttura, in modo che possa fungere da commento e aiutarti nella comprensione.
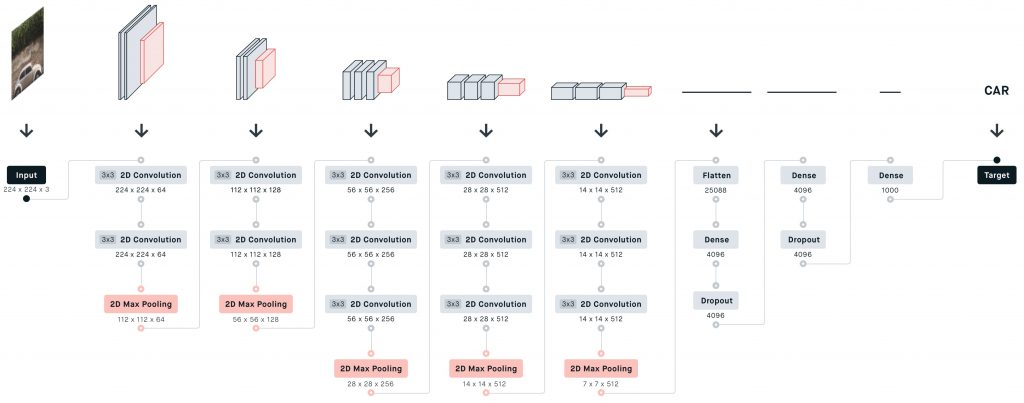
Primo Stack
Iniziamo.
Applichiamo 64 kernels, filtri convoluzionali bidimensionali di 3×3 con stride 1 e padding 1.
All’output di 224x224x64 applichiamo poi un altro filtro convoluzionale bidimensionale identico al precedente.
L’output, dimensionalmente inalterato, subisce una trasformazione con la sovrapposizione di un max pooling layer bidimensionale che produce un volume finale per il primo layer della VGG-16 di 112x112x64.
Secondo Stack
Il numero di kernel raddoppia: 128 filtri convoluzionali bidimensionali, sempre da 3×3 producono un volume iniziale di 112x112x128, a cui applichiamo un altro filtro convoluzionale e infine un max pooling layer che produce un output finale di 56x56x128.
Terzo Stack
Preleviamo l’input del layer precedente applicando 256 kernel di dimensioni 3×3, bidimensionali.
Lo facciamo 3 volte.
Al risultato, sovrapponiamo un max pooling layer per ottenere un output di 14x14x256 che finisce dritto al quarto layer.
Quarto Stack
Per 3 volte in successione, 512 kernels 3×3 manipolano i dati e in seguito all’applicazione di un max pooling otteniamo un volume finale di 14x14x512.
Quinto Stack
Simile al quarto: 3 layer convoluzionali e 1 di max pooling, che produce un output di 7x7x512.
Sesto Stack
Inizia la rete neurale profonda.
Un primo layer appiattisce il volume di 7x7x512 attraverso 25088 neuroni fully connected a un dense layer di 4096 neuroni a loro volta connessi a un dropout layer di altrettanti neuron.
Settimo Stack
Primo dense layer di 4096 neuroni e secondo dropout layer di altrettanti neuroni.
Ottavo Stack
Completa l’architettura l’output layer tipo dense con 1000 neuroni, tante le classi da prevedere.
VGG Neural Networks
Le reti VGG sono state utili nella definizione di nuove loss function quali il perpertual loss e il texture loss.
Infine, è stata progettata una variante più profonda della VGG-16: la VGG-19.
Qui la pubblicazione ufficiale della VGG-16
Le domande frequenti sulle reti VGG
Ho raccolto per te alcune domande frequenti sulle reti neurali VGG: le risposte sono utili per fissare i concetti e chiarire eventuali dubbi.
Per il momento è tutto.
Per aspera, ad astra.
Un caldo abbraccio, Andrea



