
AlexNet è un’architettura di rete neurale convoluzionale ampiamente impiegata nel riconoscimento delle immagini: una delle 4 CNN Networks che esploreremo.
Un Deep Learning Engineer mastica backpropagation e cost function a colazione, progettando CNN Networks a colpo d’occhio.
Quanto è bella questa frase.
Ora: fermi tutti!
Hai letto il post sul LeNet-5?
Ottimo Ottimo.
Una rapida ripassata anche alle CNN e iniziamo a capire come sia davvero strutturata questa rete neurale convoluzionale!
AlexNet: 2012 ImageNet ILSVRC winner
L’AlexNet è un’architettura di rete neurale convoluzionale che nel 2012 vinse il ILSVRC (Imagenet Large Scale Visual Recognition Challenge), surclassando quelle esistenti di un discreto margine.
Giusto per avere qualche riferimento: l’errore su cinque previsione fu del 17%, mentre il secondo classificato fece segnare un valore del 26%.
Le somiglianze con la LeNet-5 sono evidenti benché questa architettura sia più larga e profonda, e preveda in successione diversi layer convoluzionali anziché alternarli a livelli pooling.
Caro il mio marinaio, il vento in burrasca e il moto ondoso faticano la navigazione: abbiamo bisogno di più spinta dalle vele.
Timoniere, tutto a dritta.
Insensati riferimenti alla vita da lupo di mare a parte, esploriamo l’architettura di questa CNN Network.
La LeNet-5 gestisce immagini a singolo canale in scala grigi di dimensioni contenute: 37×37.
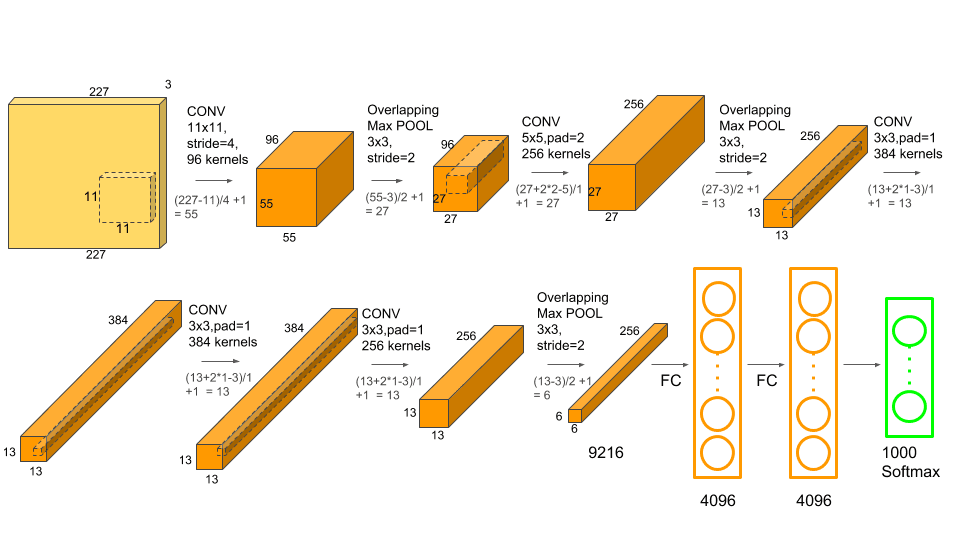
L’AlexNet porta le dimensioni iniziali a 227x227x3: tre canali, permettendoci di gestire immagini a colori (schema RGB).
Per studiare e comprenderne meglio la struttura, ti consiglio di affiancare l’immagine di cui sopra al testo.
Per un double check dei calcoli, queste sono le formule:
[latexpage]
$$
\text { output width }=\frac{W-F_{w}+2 P}{S_{w}}+1
$$
$$
\text { output height }=\frac{H-F_{h}+2 P}{S_{h}}+1
$$
Una breve legenda dei parametri meno intuitivi:
Fh – Filter Height
Sh – Stride Height
P – Padding
Bene.
Procediamo.
Prima convoluzione
Iniziamo applicando 96 filtri convoluzionali (che tecnicamente chiamiamo kernel, quindi 96 kernel) di dimensioni 11x11x3 con uno stride (lo spostamento della finestra di lettura) di 4 (pixel) e padding 0.
L’output derivante (feature maps) ha un volume di 55x55x96.
A questo sovrapponiamo un layer di max pooling avente dimensioni di 3×3 con stride 2 per ridurre le dimensioni a 27x27x96 e infine applichiamo Local Response Normalization (LRN) che prevede l’ausilio dell’ activation function Rectified Linear Unit (ReLU) per incoraggiare un fenomeno d‘inibizione laterale (lateral inhibition).
L‘inibizione laterale è un concetto tratto dalla Neurobiologia che si riferisce alla capacità di un neurone di ridurre l’attività di quelli vicini.
In una Deep Neural Network (DNN) l’impiego della local inhibition consente di migliorare il contrasto facendo sì che il valore massimo dei pixel locali possa eccitare i neuroni successivi.
Servirebbe un articolo a parte per comprendere appieno la Local Response Normalization. Per il momento limitiamoci a questo.
Ora abbiamo sempre un volume di 27x27x96 e siamo pronti alla seconda convoluzione.
Seconda convoluzione
Questa volta applichiamo 256 kernel di dimensioni 5x5x48 con stride 1 e padding 2.
Il padding, ora presente, è un bordo di pixel nulli (0) aggiuntivo usato per controllare la dimensione dell’output.
Il risultato? Un volume di 27x27x96
A questo sovrapponiamo un Max Pooling 3×3 con stride 2, per ottenere un volume di 13x13x256 e nuovamente il LRN che applica una trasformazione ma mantiene inalterate le dimensioni.
Possiamo iniziare a toccare con mano l’unicità dell’AlexNet rispetto ad altre architetture: iniziano i convolutional layer in successione
Terza convoluzione
384 kernel con dimensioni 3x3x256, stride 1 e padding 1 producono un output di 13x13x384.
Quarta convoluzione
384 kernel con dimensioni 3x3x192, stride 1 e padding 1 producono un output di 13x13x384.
Quinta Convoluzione
256 kernel con dimensioni 3x3x192, stride 1 e padding 1 producono un output di 13x13x256.
A questo sovrapponiamo un Max Pooling 3×3 con stride 2 per ottenere 6x6x256 feature maps.
AlexNet Deep Neural Network
Infine la nostra rete neurale profonda composta da 3 Fully Connected (Dense) Layer:
- 6th: Fully Connected (Dense) Layer di 4096 neurons
- 7th: Fully Connected (Dense) Layer di 4096 neurons
- 8th: Fully Connected (Dense) Layer di 1000 neurons (perché le classi da prevdere erano 1000)
Per calcolare la perdita, SoftMax.
Numero di parametri da imparare?
60mln
Esiste una variante dell’AelxNet chiamata ZF Net sviluppata da Matthew Zeiler e Rob Fergus. Vinse ILSVRC l’anno successivo cambiando sostanzialmente qualche hyperparameter tra cui lo stride e le dimensioni del kernel (kernel size).
Per il momento è tutto!
Un caldo abbraccio, Andrea.



