
Un Merkle Tree è una struttura dati efficiente per verificare che un dato appartenga a un insieme esteso di elementi. È comunemente impiegato nelle Peer to Peer network in cui la generazione efficiente di prove (proof) contribuisce alla scalabilità della rete.
Capire i vantaggi di questa struttura ci tornerà utile nel nostro percorso di esplorazione delle blockchain pubbliche, cominciato con la definizione di Ethererum e continuato con la dissezione del modello di contabilità di Bitcoin.
Ora esploriamo invece com’è fatto e a cosa serve un Merle Tree.
La struttura ad albero
La prima cosa da conoscere di una struttura ad albero è la seguente: è logicamente capovolta.
In che senso? Rispondimi: dove si trovano le radici di un albero? E le foglie?
Perfetto, rispettivamente sotto terra e in aria. Ora immagina di ruotarlo di 180 gradi. Le radici in aria e le foglie a terra. Così è fatta una struttura ad albero. In più, anziché avere molte radici ne troveremo solo una.
Osserva il seguente diagramma
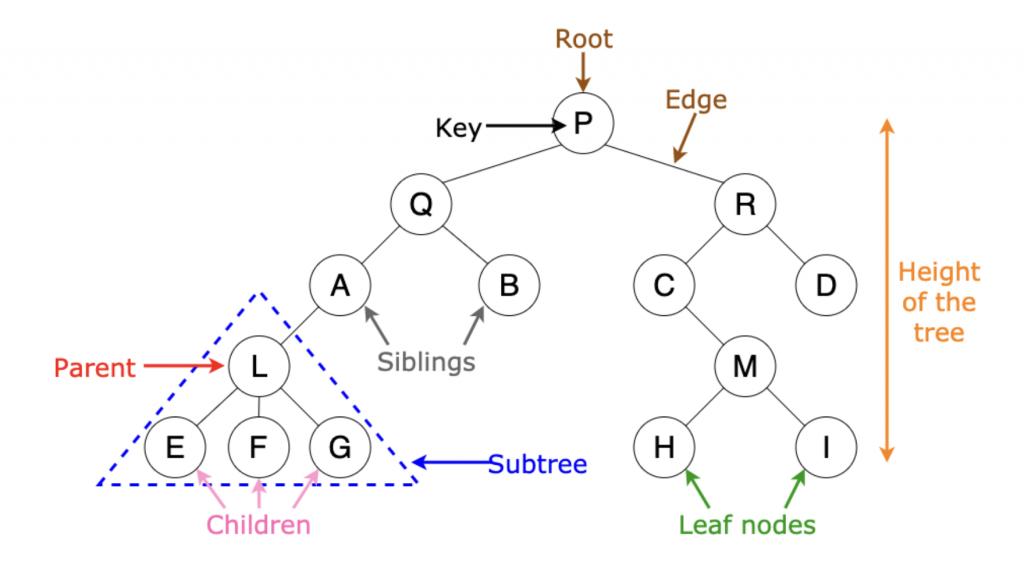
Possiamo allora identificare i seguenti componenti di base:
- nodo (node): l’unita base dell’albero. In riferimento ai nodi limitrofi, può essere padre (parent node) e/o figlio di un altro nodo (children node)
- chiave (key): il valore del dato contenuto all’interno del nodo.
- radice (root): il padre ultimo dei nodi, quello da cui tutto ha origine (o fine, a seconda dei punti di vista)
- parenti (siblings): due nodi figli accomunati dallo stesso padre e disposti sul medesimo livello
- subtree: all’interno di un albero di grandi dimensioni possiamo isolare alberi più piccoli con nuove relazioni.
Esistono diverse strutture ad albero, semplici e complesse, differenziate per proprietà caratteristiche. Una struttura piuttosto comune è ad esempio l’albero binario (Binary Tree) in cui ciascun nodo ha al più due nodi figli. Un’altra è il Merke Tree.
Seguimi.
Merke Tree: le componenti
Prima di procedere dobbiamo definire un vocabolario condiviso. In questo modo sarà più semplice per me spiegarti, e per te capire, le logiche in atto all’interno di questa particolare struttura ad albero. Avremo allora:
- Merkle tree: una struttura ad albero impiegata per la validazione dei dati
- Merkle root: la radice dell’albero, costituita da un hash derivato da quello degli altri elementi dell’albero.
- Merkle path: costituisce l’informazione di cui l’utente (il prover) ha bisogno per calcolare la Merkle root a partire da un singolo elemento di cui si intende validarne l’appartenenza. Il Merkle Path è usato nel processo di ottenimento della Merkle Proof.
- Merkle proof: prova l’esistenza di un valore (e.g. una transazione) in una specifica struttura ad albero (e.g. che codifica tutte le transazioni in un blocco) senza avere bisogno di tutti gli altri valori (i.e. tutte le transazioni). Include il merkle root e il merkle path.
Merkle Tree in Bitcoin
In Bitcoin i Merkle Trees sono usati per salvare ogni transazione minata in modo efficiente. Diamo uno sguardo all’architettura di un blocco per meglio capirne il ruolo.
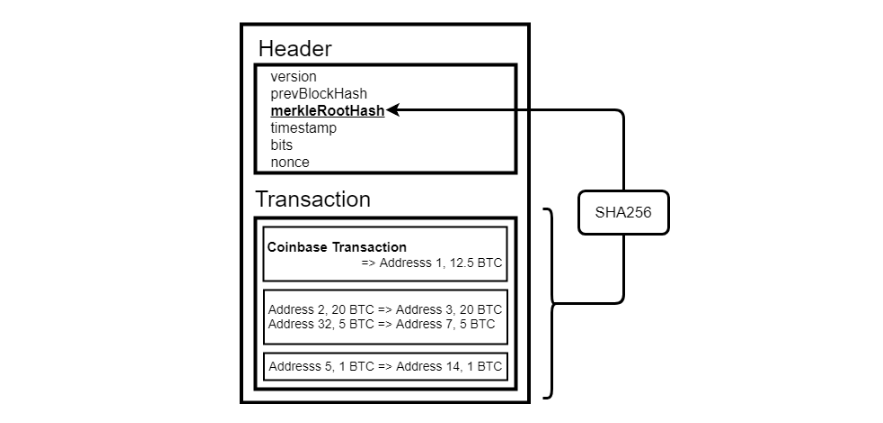
All’interno di ogni blocco devono essere contenute un numero variabile di transazioni, a seconda della congestione della rete. Tuttavia non possiamo permetterci di salvare il formato grezzo dei dati, poiché le dimensioni raggiungerebbero in fretta numeri di difficile gestione. Ci serve qualcosa che riduca lo spazio; è necessario il ricorso a una struttura dati efficiente: il Merkle Tree.
In pratica tutte le transazioni concorrono a creare un singolo albero e ciò che viene salvato nel blocco, e nella blockchain immutabile di conseguenza, è l’hash della radice o il Merkle tree root hash.
Salvando solamente l’hash della radice dell’albero possiamo ora trasferire l’incombenza della memorizzazione delle transazioni grezze a una base dati off-chain. I full-node usano ad esempio un LevelDB. Passiamo quindi da migliaia di transazioni con decine di parametri a una singola stringa alfanumerica.
Direi che il guadagno è più che ottimo.
Il principale vantaggio nell’impiego del Merkle Tree è dunque la possibilità minimizzare la dimensione complessiva della blockchain (in termini di dati). Dobbiamo infatti ricordare che data la natura dell’utilizzo la crescita è perpetua, per cui l’impiego di una struttura dati efficiente è fondamentale. Contenendo la crescita incentiviamo la creazione di nodi completi (full-nodes) contribuendo alla decentralizzazione della rete (quantomeno in teoria).
Merkle Proof
Codificare grandi quantità di dati in modo efficiente è solo una faccia della medaglia. Questo lavoro sarebbe infatti frivolo se non consentisse di verificare in modo altrettanto efficace l’appartenenza di un dato all’albero di cui conosciamo il root hash. Una verifica simile è definita Merke Proof, ovvero una prova che confermi l’esistenza dell’hash di un dato (e.g. una transazione) come foglia (leaf) o ramo (branch) dell’albero (Merkle Tree). In questo modo per provare che una transazione sia esistita in un punto nel tempo della blockchain è sufficiente fornire una Merkle Proof.
Facciamo un esempio pratico. Consideriamo allora il seguente Merke Tree che codifica le prime otto lettere dell’alfabeto in una sola Merke Root chiaramente sotto forma di hash, l’Hash(A ~ H).
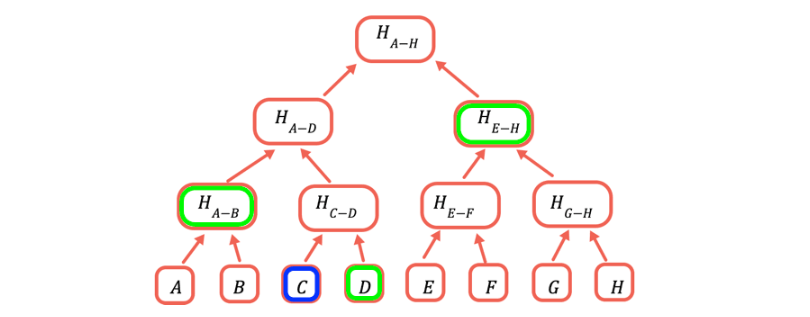
Ora supponiamo di voler verificar che la lettera C (in blu) sia effettivamente contenuta nell’albero. Per generare la Merkle Proof, anziché ricreare l’intero albero a partire dalle 8 lettere (che potrebbero invece essere transazioni complesse con decine di parametri) avremo bisogno solamente di 3 elementi: il dato D, l’ Hash(A – B) e l’ Hash (E ~ H). Saremo così in grado di costruire il Root Hash (A ~ H) e confermare che sia identico a quello fornito inizialmente.
Questo implica una complessità computazionale di tipo logaritmico O log(n) rispetto al numero di elementi base (foglie) che compongono il Merkle Tree.
Infine, contestualizzando la verifica di un Merkle Tree, identifichiamo due parti: quella del Prover e del Verifier.
- Prover: effettua i calcoli necessari per creare la merkle root (un hash)
- Verifier: non ha bisogno di conoscere tutti i valori per sapere con certezza che un valore sia presente nell’albero
Da questo punto di vista il Merkle Tree sono un grande beneficio per il Verifier.
Casi d’uso dei Merkle tree
Ricapitolando, i merkle tree sono:
- strutture dati efficienti in termini di spazio (data storage) e computazione (data computation)
- ottime per scalabilità e decentralizzazione
In altri termini consentono di
- Ridurre significativamente la memoria necessaria per verificare l’integrità dei dati e provarne l’inalterazione
- Ridurre la quantità dei dati da condividere tra i nodi di una rete (nel caso delle reti Peer to Peer questo è una fattore fondamentale) per la verifica delle transazioni. In questo modo aumentiamo l’efficienza della blockchain.
- Effettuare il Simple Payment Verification, verificando una transazione senza scaricare l’intero blocco o la blockchain stessa. Il risultato è la possibilità di inviare e ricevere transazioni usando un nodo client leggero: quello che comunemente chiamiamo wallet.
Per il momento è tutto.
Per aspera, ad astra.
Un caldo abbraccio, Andrea


