
La curva ROC, o ROC Curve, acronimo di receiver operating characteristic curve, è una metrica comunemente impiegata nel determinare le performance di un classificatore.
Può quindi essere impiegata nei problemi di classificazione, per valutare le prestazioni di un modello di machine learning.
Continua a leggere…
Devi sapere che la ROC Curve è facile da comprendere: seguimi allora alla scoperta di questa affascinante, e curiosa, metrica in una spiegazione semplice in italiano della curva ROC!
Saremo rapidi, e concisi.
A nessuno qui piace perdere tempo.
The ROC Curve | Dov’è il ricevitore?
La traduzione italiana è interessante: “curva della caratteristica di funzionamento del ricevitore”
Evidentemente ci sfugge qualcosa.
Accendiamo la macchina del tempo, e assaggiamo un pizzico di storia.
Durante la seconda guerra mondiale, dopo l’attacco a Pearl Harbor del 1941, l’esercito americano cominciò a investire in ricerche per aumentare l’efficacia nel riconoscimento dei velivoli nemici giapponesi dai tracciati radar, allora poco precisi.
La statistica corse in aiuto introducendo una metrica per valutare l’abilità degli operatori radar nel compiere le importanti decisioni sulla natura dei velivoli.
Tale metrica prese il nome di caratteristica di funzionamento del ricevitore, in inglese receiver operating characteristic.
Trattandosi di una curva, divenne nota come ROC Curve.
Le basi da cui la metrica muove sono generiche, pertanto la ROC Curve cominciò a essere presto impiegata in altri ambiti, dalla psicologia alla medicina.
Oggi, a usiamo nel machine learning.
Perché è utile la ROC Curve?
Prima di capire come si generi la ROC Curve lascia che ti spieghi perché sia importante.
Abbiamo detto che la Curva ROC è una metrica per la valutazione delle prestazioni di un classificatore.
Consideriamo allora una cosa fondamentale.
Prendiamo per semplicità un classificatore binario, con due possibili valori predetti.
Ad esempio, uno che ci dica se un viaggio sia avvincente o tedioso sulla base di alcune features che per il momento possiamo tranquillamente trascurare.
Il nostro obiettivo è partire alla scoperta di nuove culture e tornare energici e rinvigoriti, quindi la classe avvincente sarà la nostra positive label, contrapposta alla negative label tedioso.
Ora, ragioniamo insieme.
Tieni forte, perché la statistica è piena di termini doppi che indicano la stessa identica cosa: con la giusta concentrazione, sono certo diventerai master in tutto.
Allora seguimi.
La previsione del nostro modello può essere corretta o errata per ciascuna label, quindi abbiamo 4 possibili outcome:
- avvincente (corretta) [true positive]
- avvincente (errata, i.e. Il viaggio era tedioso) [false positive]
- tedioso (corretta) [true negative]
- tedioso (errata, i.e. Il viaggio era avvincente) [false negative]
Benissimo!
Un momento però.
Rifletti un secondo su come comunicheresti il risultato a una tua collega.
Avremmo bisogno di una metrica, di un valore, che esprimesse tutte le informazioni e consentisse un’agevole discussione.
La ROC Curve, o curva ROC, corre in nostro soccorso.
È il tracciato grafico di due metriche: il true positive rate e il false positive rate.
La parola rate deve farti pensare a un rapporto: non è un numero assoluto, bensì una percentuale.
Per comprende la curva ROC al meglio lascia allora che ti presenti tre metriche chiave:
- sensitivity (o recall)
- fall-out
- specificity
Sensitivity, True Positive Rate
Il true positive rate è anche chiamato Recall (recupero) o Sensitivity.
È la metrica che, unita al positive predicted value (Precision, precisione) costituisce F1 Score.
Per il momento però non complichiamoci troppo l’esistenza, e soffermiamoci sul True Positive Rate.
Ho preparato per te una flash card che agevola lo studio.
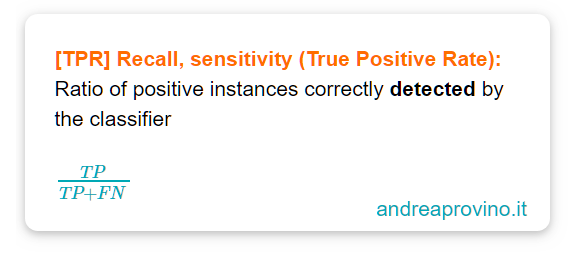
Più nello specifico, il True Positive Rate è il valore d’istanze positive correttamente identificate da un classificatore.
Benissimo, passiamo al secondo valore.
Fall-Out, False Positive Rate

Il false positive rate, anche conosciuto con il particolare termine Fall-Out, esprime il valore d’istanze negative incorrettamente identificate.
Un doppia negazione che ne complica l’interpretazione.
Possiamo allora dire che il FPR esprime il numero d’istanze che pensiamo siano negative ma che in realtà non lo sono.
In pratica? La probabilità di falso allarme.
Esiste poi una terza metrica, il True Negative Rate.
Specificity, True Negative Rate
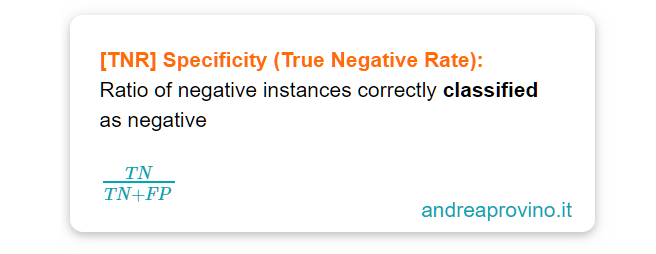
Il true negative rate, definito come specificity, esprime il rapporto d’ istanze negative correttamente identificate.
Il fall–out, cioè il false positive rate, equivale a 1 – Specificity, quindi 1 – true negative rate.
Tutto questo per dire che la ROC Curve è il grafico tra Recall e 1 – Specificity.
Ancora una volta c’è un compromesso: tanto più alta una metrica, tanto più bassa la restante.
Quanto più basso è il recupero, cioè quanto più alto è il numero d’istanze positive identificate dal classificatore, tanto più alto sarà il numero di falsi positivi creati.
Questa è una regola fondamentale da tenere a mente, che si collega al discorso sulla differenza tra precision e recall che ti ho spiegato in un altro post.
AUC: Area Under the ROC
Tante parole, senz’altro utili.
Non so te, ma io ho bisogno di visualizzare la teoria.
Allora ecco l’aspetto della curva ROC:
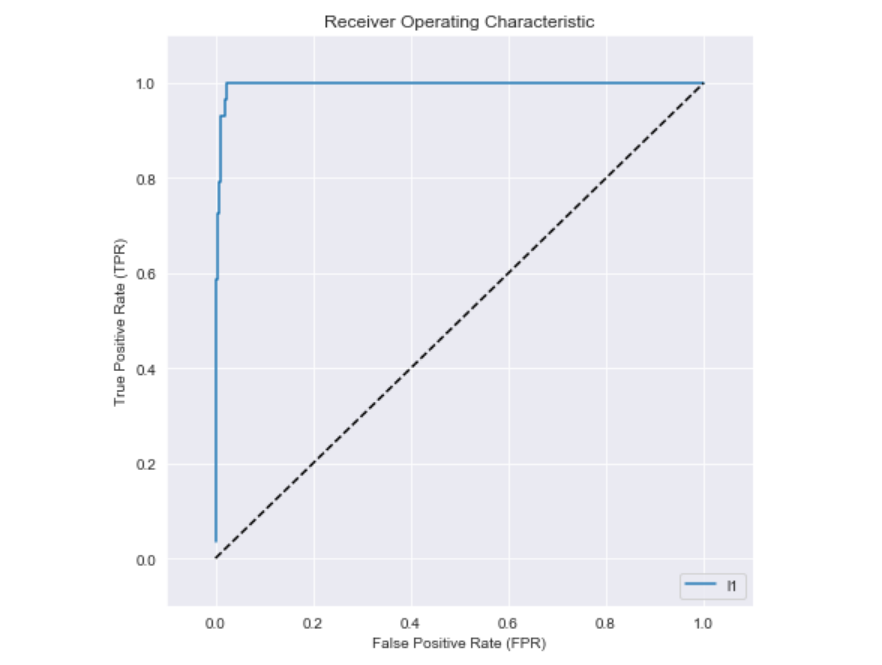
Ti faccio notare la linea tratteggiata diagonale nera e quella continua blu.
Entrambe definiscono un’area a loro sottostante.
Questa area è estremamente importante a livello concettuale.
Come Data Scientist, o machine learning engineer, è nostro compito massimizzare l’area al di sotto della ROC Curve, la linea continua blu in figura, per massimizzare quindi ciò che definiamo: Area Under the ROC Curve, abbreviata in AUC.
Un classificatore ideale avrà quindi area pari a 1.
Un classificatore con logica casuale, area pari a 0.5.
Nel range intermedio, ogni applicazione che vedrai nel mondo reale.
L’obiettivo è quindi quello di far sì che la curva sia quanto più lontana dalla linea casuale e vicina al top-left corner.
Quindi sappiamo cos’è, e come tracciarla.
In che modo riusciamo a interpretarla però?
Come si legge l’AUC?
L’AUC è utile perché fornisce una misura delle perfomance su tutte le soglie (threshold) di classificazione.
Può essere interpretata in modi differenti, uno dei quali la considera come la probabilità che il modello classifichi un esempio positivo casuale più in alto di un uno negativo.
Mi spiego meglio.
Considera questa sequenza di campioni effettivamente positivi e negativi (true positive, e true negative), ordinati per valore crescente predetto dal modello.

In questo caso, un modello di regressione logistica esprime un valore in virgola mobile (e.g. 0.4, 0.7) per indicare l’appartenenza alla classe negativa (0) o positiva (1).
AUC costituisce dunque la probabilità che un campione casuale positivo (i.e. Un pallino verde) sia posizionato alla destra di un campione casuale negativo (i.e. Un pallino rosso).
I motivi per cui tornano utili inoltre, sono i seguenti:
- AUC è scale-invariant, ovvero agnostica ai valori assoluti, misurando come le previsioni sono classificate.
- AUC è classification-threshold-invariant, ovvero agnostica alla soglia di classificazione (e.g. considerare campione positivo se soglia superiore a 0.75)
Precision / Recall vs ROC Curve
Come puoi vedere, la ROC Curve è simile alla Precision / Recall Curve.
Come possiamo allora scegliere la metrica ideale, quando usare l’una, quando l’altra?
Dipende dal problema.
Dovresti preferire la Precision / Recall Curve ogni qualvolta:
- affronti un imbalanced classification problem, in cui la classe positiva è rara (cioè in numero considerevolmente inferiore a quella negativa)
- sono più importanti i falsi positivi che i falsi negativi o viceversa (ottimizzare un tipo di errore di classificazione)
In tutti gli altri ambiti, la ROC Curve è invece la scelta da preferire.
Per usarla, è sufficiente ricorrere all’implementazione di sklearn, sebbene possa essere in questo caso usata solo per task di classificazione binaria.
Domande frequenti sulla curva ROC
Ho pensato di raccogliere per te alcune domande frequenti sulla Curva ROC.
Potrebbero tornarti utili per ripassare.
Per il momento è tutto.
Per aspera, ad astra.
Un caldo abbraccio, Andrea



