
In un classifciatore binario (binary classifier) una matrice di confusione (confusion matrix) fornisce molte informazioni. Spesso sono però utili metriche più concise: ecco la precisione e il recupero (precision recall).
Prima di addentrarci alla scoperta del singificato di questi due, complessi, termini diamoci una rinfrescata con la definizione di confusion matrix, e spolveriamone la logica di funzionamento.
Ci servirà
Come ben sai, in un classificatore binario solo due possono essere le classi della label:
- classe positiva, per il valore di maggior interesse
- clase negativa, per la restante.
Ti faccio notare che usiamo un binary classifier come semplificazione, ma il discorso è estendibile ai multi lable classificator (con più di due label, come nel caso di identificazione delle cifre scritte a mano => 10 label)
Precision Metric
La precisione, in inglese precision, è l’accuratezza con cui il sistema di machine learning prevede le classi positive.
E’ definito come il rapporto tra i true positive e la somma dei true positive e false positive:
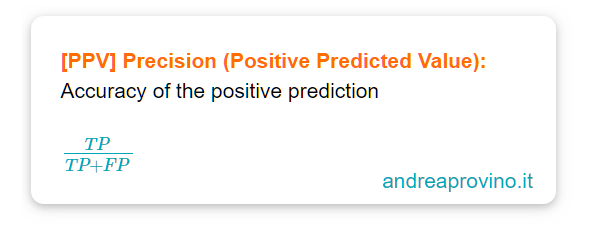
La precisione è una dark lady. La sua definizione fa si che basti avere una previsione positiva corretta per avere una precisione del 100%, oppure nesuna previsione falsa positiva e comunque la precisione sarebbe del 100%.
In pratica è come quando venivi interrogato alle superiori: hai studiato poco e sei tentennante: rispondi con cautela. Finisce l’interrogazione ti chiedono come sei andato e rispondi “Benissimo, mi ha fatto una domanda e ho risposto bene! 10/10” E pensano che tu abbia preso 10, invece hai preso 5.
Questo perché non stiamo considerando a quante, delle domande che ti hanno fatto, hai risposto in modo sbagliato.
Ecco perché la precision da sola non basta, ed è associata ad un’altra metrica: recall.
Recall Metric
Il recupero, in inglese recall, è anche chiamata sensitivity o true positive rate: indica il rapporto di istanze positive correttamente individuate dal sistema di machine learning.
La formula è:
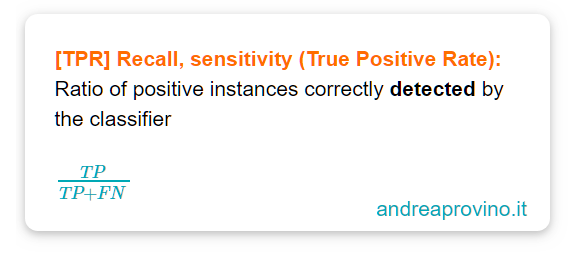
Macchinso e teorico. Vogliamo le mani in pasta.
Cioè: “Delle 10 domande che ti ho fatto, a quante hai risposto correttamente?
Una sola?
Allora sei stato molto preciso nel rispondere a quella sola domanda in modo corretto (perché la precisione è calcolata solo sulle classi positive) ma hai mancato altre 9 domande…”
F1 Score: Precision and Recall
Spesso è conveniente fondere Precision and Recall in una sola metrica chiamata: F1 score.
F1 Score è una media armonica cioè il reciproco della media aritmetica dei reciproci.

Più nello specifico F1 score è l‘harmonic mean of precision and recall.
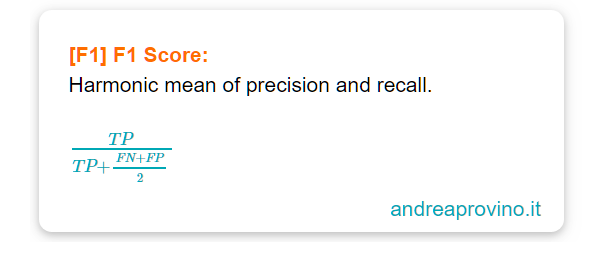
Rispetto ad una media convenzionale, quella armonica attribuisce un peso maggiore ai valori piccoli. Questò fa sì che un classificatore ottenga un alto punteggio F1 solo quando precisione e recupero sono entrambi alti.
Avere un’alta precisione e un’alto recupero non è sempre utile. In alcuni casi e contesti ricerchiamo uno squilibrio tra le due metriche.
Ci sono problemi che richiedono un’alta precisione e un basso recupero e viceversa.
Comprendiamoli meglio.
Safe Video Case Study
Sappiamo che il machine learning altro non è che un efficace strumento per risolvere un reale problema.
Dobbiamo quindi comprendere bene quali siano le regole del gioco, affinché la nostra strategia si riveli vincente. Fuori di metafora, questo significa impiegare il domain knowledge.
Applicando questo concetto all’argomento fin qui trattato, possiamo dire che alcuni business non sempre desiderano il risultato idealmente migliore: lo squilibrio diventa la soluzione.
Possiamo infatti incontrare realtà capaci di accettare falsi negativi e di non tollerare assolutamente falsi positivi.
Immaginiamo di avere un classificatore allenato a riconoscere e distinguere video sicuri per bambini di tenera età.
Configuriamo il problema con:
- safe, classe positiva
- danger, classe negativa
E’ preferibile optare per un sistema che sacrifichi qualche video sicuro ma che blocchi tutti quelli pericolosi, a costo quindi di classificare pericoloso qualche video sciuro (tanti False Negative).
Invece tutti i video sicuri saranno effettivamente tali, perché vogliamo avere zero Falsi Positivi
In questo modo avremo una low recall, con high precision.
Predictive Maintenance Case Study
Ora intendo sotto porre alla tua attenzione un secondo esempio.
Ancora una volta il domain knowledge è fondamentale per designare la win condition del nostro lavoro: la metrica che ci dice quando possiamo essere fieri del risultato.
Quando si parla di predictive maintenance, ossia di manutenzione predittiva, intendiamo evitare fermi macchina prolungati.
L’obiettivo è sostituire preventivamente pezzi a rischio rottura, minimizzando l’interruzione del funzionamento e riducendo i costi.
Riflettici un secondo.
In un contesto simile, un falso negativo potrebbe potenzialmente far deragliare un treno, mentre un falso positivo far spendere all’azienda inutili somme di denaro.
La soluzione perfetta?
Dobbiamo purtroppo ricordare che gli unicorni non esistono.
Queste metriche sono come i piatti di una bilancia: se alzi uno, l’altro scende.
Spesso dunque, occorre un compromesso che definiamo: Precision/Recall Tradeoff.
Prima di salutarti, ho pensato di selezionare per te alcune domande, con relative risposte, che potresti sollevare in merito alla questione precision vs recall.
Precision vs Recall and F1 Score
Per il momento è tutto.
Per aspera, ad astra.
Un caldo abbraccio, Andrea



