
Il Federated Learning è una nuova tecnica di machine learning training che consente lo sviluppo di un modello su di un dataset distribuito.
Convenzionalmente un modello di AI è allenato su un singolo dataset dislocato su un una singola macchina (leggasi server o cluster, inteso come sistema informatico e non il risultato del, ad esempio, DBSCAN).
Questo approccio richiede dunque che i dati siano aggregati.
Il problema?
Non è sempre che detto che la centralizzazione dei dati sia fattibile.
Perché?
Le ragioni possono essere diverse: da quelle legali, a quelle confidenziali (e.g. Un’azienda non intende compromettere la propria Proprietà Intellettuale.)
Ecco che entra in gioco il Federated Learning: invece di prelevare tutti i dati dai proprietari (owner) e inviarli al sistema centralizzato per l’allenamento (centralized learning), prevede che siano i modelli stessi a essere portati laddove i dati risiedano (i.e. in tutte le locazioni sulle infrastrutture possedute dai data owner).
Per un approccio più pacioccoso e coccoloso, Google offre dei disegni comico-illustrativi a riguardo.
Federated Learning Case Study
Immaginiamo il seguente scenario reale.
Dobbiamo creare una piattaforma che faciliti la ricerca e analisi condotta su una serie di dati privati e distribuiti garantendone la privacy. (privacy-preserving research)
Un tale sistema consentirebbe ai ricercatori di compiere analisi innovative (groundbreaking) senza richiedere l’accesso ai dati studiati, o a una copia di essi.
Questo renderebbe finalmente disponibili una moltitudine di dati legati ad esempio al settore medico e finanziario, prima congelati a causa di rischi dovuti alla possibile diffusione di informazioni private.
Magnifico! Come possiamo allora realizzare un simile progetto?
Ecco la chiave di volta: consentire ai data owner di partecipare alla ricerca mettendo a disposizione i propri dati senza tuttavia doverli caricare o trasferire, su una struttura terza centralizzata.
Si tratta di un requisito spesso bloccante per ricerche richiedenti l’accesso a dati privati.
Un blocco che conduce rapidamente a un difficile trade-off: mantenere i dati privati (sull’hardware proprietario, sicuro e affidabile) o fornirli a un ricercatore nella speranza che possano contribuire alla soluzione di questioni eticamente rilevanti? (e.g curare il cancro)
Risolvere questo compromesso richiede un cambiamento di prospettiva e la creazione di nuove premesse.
Il federated learning e la differential privacy sono due efficaci strumenti per pavimentare la strada a nuove future conquiste nel settore data science e machine learning.
Silo vs Device schemes
Possiamo classificare due schemi di applicazione del federated learning:
- Cross-silo
- Cross-device
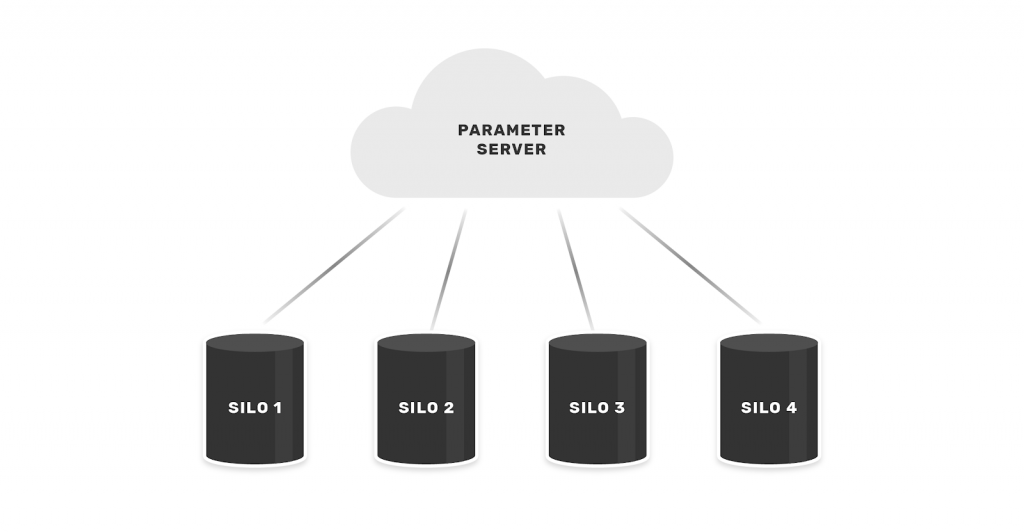
Lo schema cross-silo prevede che i dati siano presenti all’interno di più database, contenenti quindi le informazioni di una moltitudine di utenti, e partizionati per feature.
Possiamo approfondire questo schema nell’articolo accademico di Feng et Al.
L’esempio pratico è quello che coinvolga differenti istituti di credito e la necessità di creare un sistema che analizzi i loan repayment records dei vari clienti.
Siamo così in grado di prevedere la probabilità che un soggetto vada in default, e accordare di conseguenza i termini del prestito. Visivamente:
Lo schema cross-device fa invece riferimento allo scenario in cui i dati siano presenti su differenti devices. Questo richiede un partizionamento per campioni.
Il nostro pigro cervello sarà agevolato a comprendere il concetto da questa immagine:
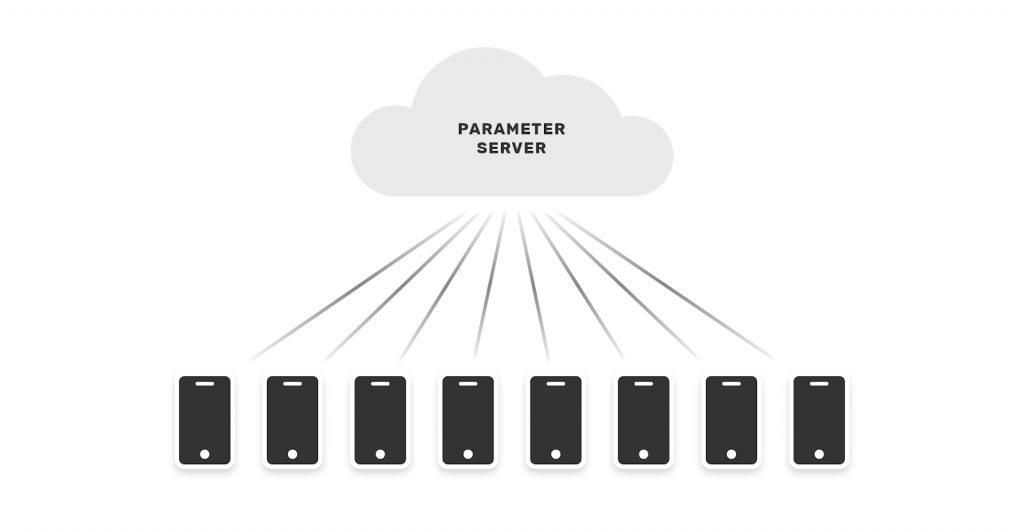
Un esempio significativo è il servizio di previsione della parola successiva offerto dall’App GBoard di Google.
Studiamone il funzionamento!
Federated Learning on GBoard
Google nel 2017 sperimentò con successo l’uso del federated learning applicandolo al servizio GBoard.
In questo caso il testo scritto dall’utente veniva analizzato e qualora una query proposta fosse stata cliccata dall’utente, i dati raccolti sarebbero stati immagazzinati e successivamente inviati in cloud per il training.
Immagino che il sistema sia tuttora in funzione! Fantastico.
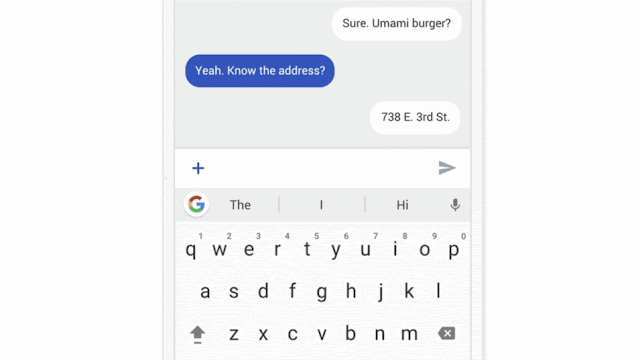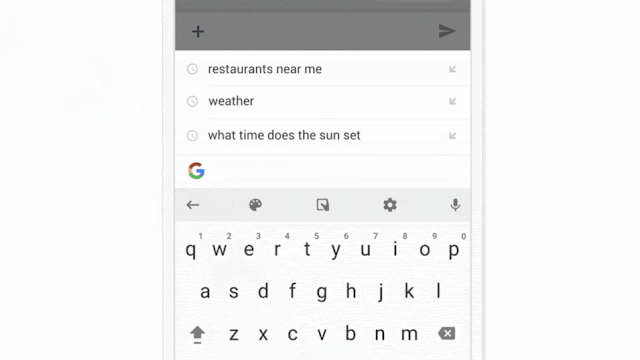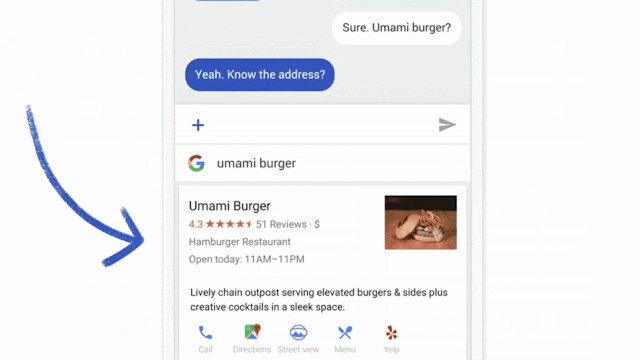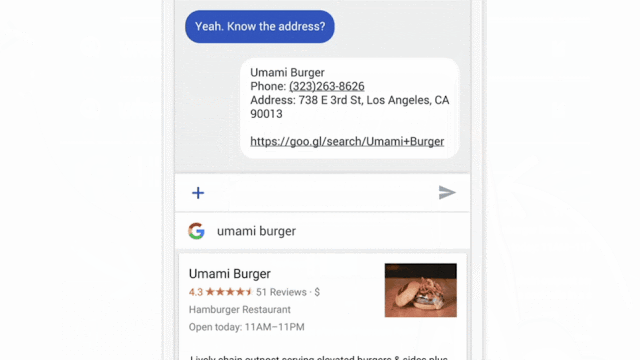
Gli ostacoli da superare nello sviluppo di un sistema di federated learning sono molteplici:
- dati presenti su milioni di dispositivi in un highly uneven fashion
- alta latenza
- bassa velocità di connessione per l’invio dei dati
- dati a disponibilità intermittente per l’allenamento.
Tecniche comuni quali l’ausilio di un Stochastic Gradient Descent (SGD) come algoritmo di ottimizzazione non possono essere utilizzati, perché facenti affidamento a dataset partizionati in modo omogeneo su server in cloud
Queste soluzioni altamente iterative richiederebbero bassa latenza e alta velocità di connessione ai dati. Premesse assenti nel federated learning.
La soluzione?
Nuovi algoritmi!
Data Partitions
Continuando il nostro studio teorico, dobbiamo sottolineare un altro aspetto.
Il Federated Learning supporta tre tipologie di partizioni dati: orizzontale, verticale e una denominata di federated transfer learning.
| Nome partizione | Descrizione Partizione |
| HFL: Horizontal partitioned FL | I dati sono distribuiti in diversi silos contenenti lo stesso feature space* e diversi samples |
| VFL: Vertically partitioned FL | I dati sono distribuiti su diversi silos conteneti diversi feature space* e gli stessi samples |
| FTL: Federated transfer learning | I dati sono distribuiti su differenti silos conteneti diversi features space* e diversi samples |
*Il feature space fa riferimento alle spazio n-dimensionale in cui le feature di un dataset (senza la label dunque) giacciono. Puoi trovare maggiori dettagli in questa risposta di stackexchange.
Abbandonando la teoria astratta per qualcosa di più concreto, un esempio di problema di apprendimento su partizione orizzontale con schema cross-silo può coinvolgere dati tipo:
- Strutturato: dati generati da software aziendali, installati su più istituzioni e / o divisi in molteplici stati, in ottemperanza ai requisiti di data localization (maggiori dettagli qui)
- Non strutturato: nell’hleatcare, documentazione clinica, tomografie e simili
In questo articolo accademico sull’applicazione del FL all’Healtcare per l’analisi degli elettroencefalogrammi, dal titolo HHHFL: Hierarchical Heterogeneous Horizontal Federated Learning for Electroencephalography di Gao et Al., troviamo un esempio di HFL.
Non finisce qui.
Prima di salutarti facciamo un accenno all’implementazione pratica del federated learning.
Federated Learning Python
Ok. Teoria fatta.
Lato tecnico pratico: cosa ci offre il mondo python open source?
Google gestisce il federated learning attraverso Tensorflow, e con l’aiuto di una sezione dedicata nella documentazione è possibile sviluppare dei sistemi che preservino la privacy.
Invece, qualora la nostra rete neurale fosse realizzata con PyTorch dovremmo ricorrere ad altre librerie.
Consideriamo ad esempio PyGrid e PySyft di OpenMined per implementare soluzioni di federated learning.
In attesa di novità e aggiornamenti, una buona giornata!
Un caldo abbraccio, Andrea.



