
DBSCAN è l’acronimo inglese di Density-based spatial clustering of applications with noise, un sofisticato algoritmo di clustering comunemente usato per il Data Mining e Machine Learning.
Un passo alla volta.
Sai cos’è il clustering?
Benissimo, se avessi qualche dubbio, un post di approfondimento su tutto quello che devi sapere sul clustering è sempre lì a disposizione per te.
Negli ultimi giorni abbiamo analizzato dei noiosi strumenti di visualizzazione dati, conoscenze fondamentali nel portoflio di ogni data scientist.
Delle particolari librerie usate, Folium è senz’altro una delle più curiose: torna particolarmente utile per la visualizzazione di dati geo-spaziali (geospatial data).
È proprio questo il punto legame con l’argomento odierno: devi sapere che DBSCAN è un algoritmo di clustering density-based particolarmente appropriato per i dati spaziali.
Ok, ora sappiamo esattamente quanto prima.
Non va bene, dobbiamo scavare più a fondo.
Per procedere sono necessarie alcune conoscenze pregresse:
- Principio di funzionamento degli algoritmi di clustering
- Termini tecnici: centroidi
DBSCAN: Density-based spatial clustering
Gli algoritmi di clustering sono un esempio di unsupervised learning, dal momento che il loro funzionamento non richiede la presenza di una label nel dataset.
Ora, tra i nomi di clustering algorithm più comuni figurano certo il K-Means e l’Hierarchical Clustering.
Quando i dati richiedono lo sviluppo di cluster dalle forme arbitrarie o gruppi di cluster limitrofi e sovrapposti, le tecniche tradizionali faticano a ottenere buoni risultati:
- Gli elementi all’interno del cluster potrebbero non condividere similarità sufficienti
- Povere performance
Le difficoltà non terminano qui.
Gli algoritmi tradizionali sono privi della nozione di outliers, il DBSCAN è invece in grado di riconoscerli evitando che questi finiscano assegnati a un cluster pur non appartenendo ad alcuno di essi: un’operazione fondamentale nel campo della anomaly detection.
Le osservazioni aberranti avvicinano a sé i centroidi dei cluster, rendendo più complessa la loro gestione.
In contrasto, altri sistemi di clustering come il DBSCAN separano regioni ad alta e bassa densità.
Evidentemente per densità ci riferiamo al numero di osservazioni entro uno specifico raggio.
Ancora una volta, ora per questioni stilistiche, il DBSCAN è un popolare sistema di clustering density-based.
Uno dei meravigliosi vantaggi del DBSCAN è la capacità d’individuare cluster dalle forme arbitrarie senza rimanere influenzato dal rumore di fondo (noise).
How DBSCAN works
Il funzionamento del DBSCAN si basa sul presupposto che se una particolare osservazione appartenesse a uno specifico cluster, dovrebbe essere vicina alla maggior parte dei samples appartenenti al medesimo cluster.
Due parametri giocano un ruolo chiave:
- radius
- minimum points
Definiamo poi dense area quella regione di spazio delimitata dalla circonferenza di raggio epsilon contenete un sufficiente numero di datapoints.
Chi definisce questo sufficiente numero ?
INFN, Istituto Nazionale di Fisica Nucleare.

Scherzi a parte, lo decidiamo attraverso minimumSamples il parametro per il minum number of datapoints.
Ecco visivamente come opera:
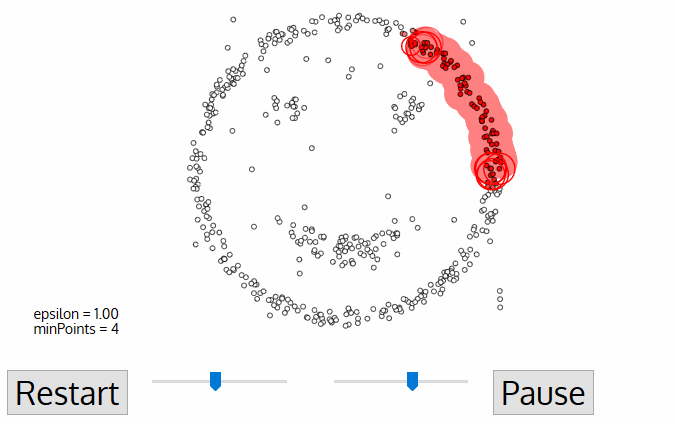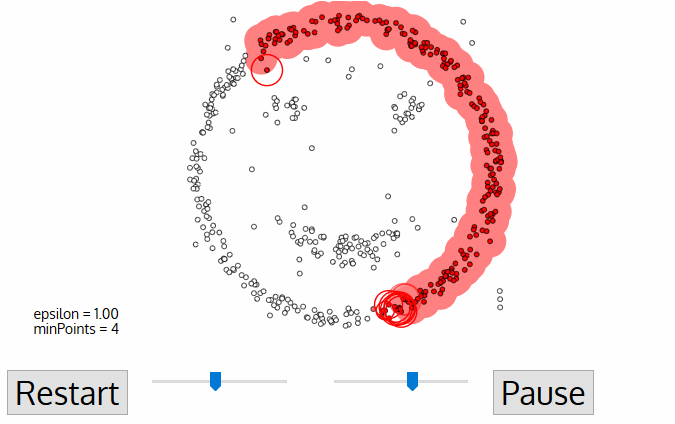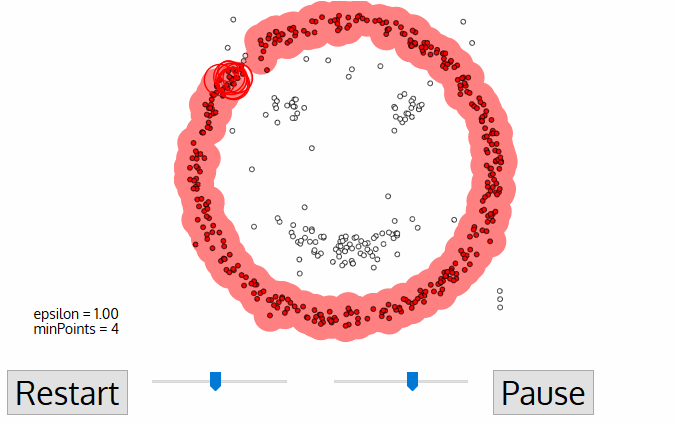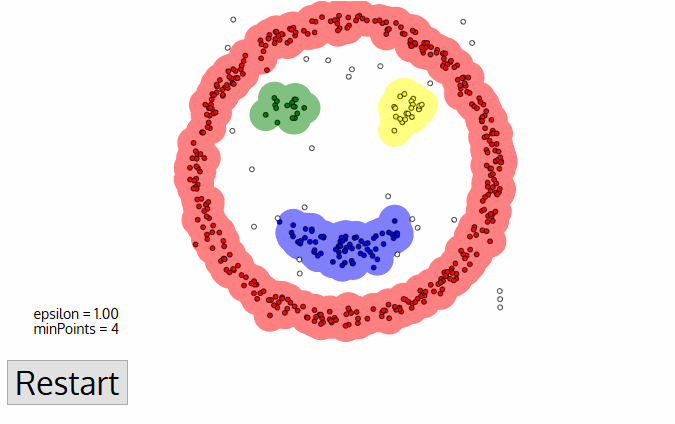
Codice
Questo articolo ha una valenza prettamente teorica.
Ho comunque deciso di riportare giusto un minimo di codice.
Qui sotto trovi lo snippet di importazione con sklearn, invece a qui il codice del DBSCAN in Python.
from sklearn.cluster import DBSCAN epsilon = 0.3 minimumSamples = 7 db = DBSCAN(eps=epsilon, min_samples=minimumSamples).fit(X)
Conclusione
DBSCAN è un sofisticato strumento di clustering density-based che:
- Identifica cluster dalle forme arbitrarie
- Determina cluster circondati, o sovrapposti, da altri cluster.
- Ha un senso di rumore
- E’ robusto agli outliers
- Non richiede la specificazione del numero totale di cluster.
Per approfondire.
Per il momento è tutto.
Per aspera, ad astra.
Un caldo abbraccio, Andrea



