
Il Credit Assignment Problem è genericamente parlando il problema di determinare quale componente di un sistema contribuisca maggiormente al successo del sistema stesso.
Trattando di machine learning, ed essendo questo un post sul Reinforcement Learning dobbiamo certamente andare nello specifico.
Diciamo allora che nel Reinforcement Learning il Credit Assignment Problem è il problema di determinare quale azione produca il massimo valore, inteso in termini di ricompensa.
Un problema tanto apparentemente banale quanto realmente complesso.
Procediamo quindi per gradi.
Seguendo la nostra breve introduzione al Reinforcement Learning, è giunto il momento di capire come il Credit Assignment Problem giochi un ruolo fondamentale nello sviluppo di un sistema intelligente.
Neural Network Policy
La tecnica che spesso usiamo insieme per comprendere un nuovo concetto è definire un ambiente, un contesto, presentando quindi un problema al suo interno risolvibile solo o anche con il concetto che intendiamo capire.
In questo post, seguiremo il medesimo processo.
Ti prometto una cosa: sarò breve e, almeno per il momento, non ti presenterò alcuna riga di codice.
Nell’introduzione al Reinforcement Learning, abbiamo compreso come una policy possa essere anche una rete neurale.
Consideriamo allora una semplice rete neurale: prende le osservazioni in input ed produce in output l’azione da eseguire.
Più tecnicamente, la rete neurale stima una probabilità per ogni azione e attraverso una selezione casuale scegliamo quella valida.
La casualità permette l’esplorazione dell’ambiente, questione che abbiamo esaminato qui.
Casualità
Sinteticamente, questo approccio permette all’agente di definire il giusto bilanciamento tra l’esplorazione (exploring) di nuove azioni e l’utilizzo (exploiting) di quelle note come funzionanti.
L’analogia classica è quella della prima volta in un ristorante: tutti i piatti del menu sono egualmente invitanti quindi casualmente ne ordini uno.
Qualora fosse di tuo gradimento, aumenti la probabilità di ordinarlo la prossima volta, anche se fai in modo che non sia mai al 100% in modo tale da non precluderti alcuna altra prelibatezza, che potrebbe essere persino migliore di quella inizialmente presa.
Te (l’agente) stai esplorando l’ambiente (il menu), compiendo azioni (ordinando) e ottenendo ricompense (piatto delizioso o meno) in cambio, così da migliorare le scelte per massimizzare il guadagno (e.g. Felicità all’uscita dal ristorante).
OpenAI Gym
Riprendiamo il nostro discorso riducendo la complessità.
Rammenti l’ambiente di OpenAI Gym con il palo sul carrello che occorre tenere in equilibrio?
CartPole?
Esatto quello che avevamo visto insieme qui.
In questo ambiente le due sole azioni sono accelerazione a destra e a sinistra, quindi la nostra rete neurale ha bisogno di un solo neurone di output.
L’output è la probabilità p dell’azione 0 (sinistra) e possiamo quindi definire anche quella 1 (destra) come 1 – p.
Pertanto se il risultato fosse 0.7, avremo il 70% di probabilità che l’azione corretta sia andare a sinistra e il 30% (1 – 0.7 * 100) di andare a destra.
Ti faccio notare un altro particolare: in questo ambiente semplificato, le azioni e osservazioni passate possono essere ignorate in sicurezza poiché ogni nuova osservazione contiene l’intero stato dell’ambiente.
Questo non vale ad esempio per un’auto a guida autonoma in cui il sorpasso dell’auto che precede nasconde la vettura all’agente, sebbene questo debba comunque essere consapevole del rischio dovuto a manovre brusche.
Anche l’assenza di un parametro come la velocità nello stato dell’ambiente, che deve essere calcolato sulla base delle posizioni passate, o in presenza di osservazioni noisy, degradate da rumore, richiede che vengano considerati gli stai precedenti.
The gredit assignment problem in a neural network
Stai per diventare un Deep Learning Engineer (kind of)!
Seguimi mentre creiamo insieme un’architettura di rete neurale.
La nostra Neural Network deve essere semplice e mappare al contempo la realtà di nostro interesse, ovvero l’ambiente virtuale di OpenAi Gym.
Sappiamo che in ogni instante abbiamo 4 osservazioni (caratteristiche del sistema virtuale), quindi definiremo un input layer di quattro neuroni, fully connected ad altrettanti neuroni dell’unico hidden layer per poi concludere il flow dei dati nel solo neurone di output (i.e. probabilità di andare a sinistra).
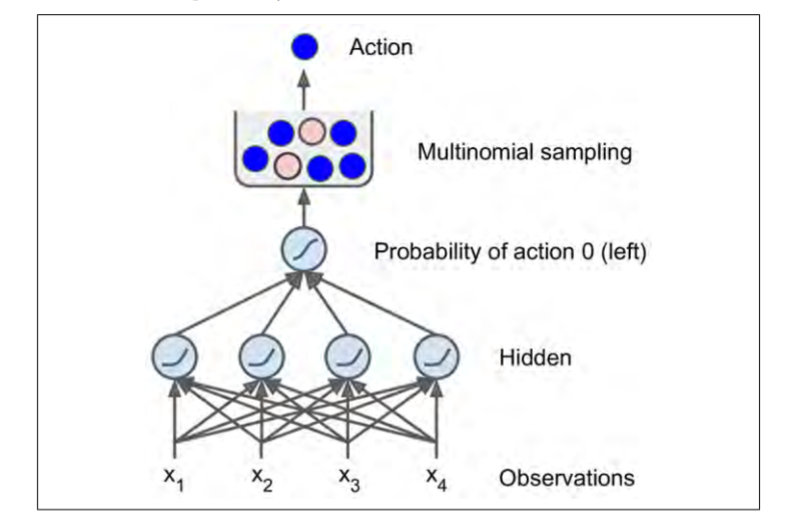
Quello che abbiamo creato è banalmente un Multy-Layer Perceptron.
In aggiunta, ti faccio notare che poiché ci aspettiamo una probabilità compresa tra 0 e 1 abbiamo bisogno di una funzione di attivazione che mappi i valori nell’intervallo desiderato: entra in gioco la funzione logistica per eccellenza, la Sigmoid Function.
Avremmo avuto bisogno di un neurone per azione, se quelle attuabili fossero state più di due, e in questo caso saremmo passati a una softmax function.
Nell’illustrazione, avrai certamente notato il Multinomial Sampling. È la fase in cui selezioniamo casualmente l’azione da compiere.
Perfetto. Ora abbiamo la nostra rete neurale, e una grande domanda in tasca.
Come diamine dovremmo fare per allenarla?
Ecco il credit assignment problem.
The Credit Assignment Problem in Reinforcement Learning
Potremmo allenare la rete neurale in modo standard, se conoscessimo a priori la migliore azione da compiere in ogni istante.
Basterebbe minimizzare il cross–entropy loss, o log loss, che misurerebbe la performance del nostro classificatore, il cui output è una probabilità tra 0 e 1, aumentando se il valore predetto divergesse da quello reale.
In questo modo sarebbe possibile classificare il sistema di machine learning come supervised learning.
In un sistema di reinforcement learning le carte in tavola cambiano.
L’unica guida che un agente ha è la penalità, un genere distribuite e ritardate.
Se il nostro agente bilanciasse il palo sul carrello per 100 steps, come potremmo stabilire quale delle azioni sia stata corretta e quale invece sbagliata?
Potremmo solo sapere che il palo sia caduto dopo 100 azioni, e certamente l’ultima non è completamente responsabile dell’esito.
Tradotto, abbiamo un problema di assegnazione.
Più formalmente, ecco il credit assignment problem: quando l’agente ottiene una ricompensa è difficile per lui comprendere quali azioni siano responsabili della ricompensa, sia essa positiva o negativa.
Occhio a una cosa: la ricompensa non è detto che sia immediata, ma può essere elargita solo in specifiche situazioni (e.g. quando il palo cade) o ritardata (e.g. Pensa a un cane che riceve un snack ore dopo essersi comportato bene).
Abbiamo dunque tra le mani un’annosa situazione.
Come la risolviamo?
Discount Rate
Una strategia comune per risolvere il credit assignment problem nel reinforcement learning è applicare un discount reate r a ogni step.
Ok. Qui abbiamo bisogno di un esempio.
Configuriamo la simulazione con 3 step e altrettante ricompense in funzione della stessa azione: l’agente si muove sempre a destra. In ordine abbiamo:
- primo step, 10 punti
- secondo step, 0 punti
- terzo step, -50 punti.
Ora applichiamo il concetto di discount rate, con valore pari a 0.8 in questo esempio. Avremo allora per la prima azione:
10 + r x 0 + r2 x (-50) = -22.
Il discount rate indica sostanzialmente al sistema quanto valore debbano avere le ricompense future, quanto sia importante il presente.
Con un valore vicino a 0 le ricompense future non contano molto se comparate a quelle immediate. Al contrario, un valore vicino a 1 indica all’agente che le ricompense future conteranno circa quanto quelle immediate.
Valori comuni di discount rate sono 0.95 e 0.99. Per darti un ordine di grandezza, un discount rate di 0.95 implica che una ricompensa 13 step nel futuro conterà circa metà di una immediata (0.9513 ≈ 0.5).
Mentre un discount rate di 0.99 fa sì che 69 step nel futuro contino quanto metà di una ricompensa immediata.
Considerazioni logiche
Ovviamente una buona azione può essere seguita da una serie di azioni sbagliate che porterebbero il palo, del nostro ormai citatissimo esempio, a cadere, e la prima azione avrebbe un punteggio molto basso.
In media però le buone azioni otterrebbero un punteggio più alto, ripetendo la simulazione molteplici volte.
L’operazione di standardizzazione assume qui un ruolo fondamentale.
Per ottenere punteggi attendibili per le azioni occorre eseguire le simulazioni svariate molto in modo da normalizzare i valori.
Ora è arrivato il momento di allenare la nostra rete neurale usando un metodo noto come Policy Gradients!.
Per il momento è tutto.
Per aspera, ad astra.
Un caldo abbraccio, Andrea.



