
TensorFlow Extended è un toolkit production-ready sviluppato da Google per la creazione di Pipeline di Machine Learning. In questo post ti spiego come funziona TensorFlow Extended (TFX) facendoti risparmiare tempo prezioso!
Sappiamo entrambi che le documentazioni ufficiali tendono a essere dispersive.
Ho pensato allora di raccogliere per te le informazioni essenziali e presentartele con estrema sintesi in questo post.
Come funziona TensorFlow Extended (TFX)?
Una pipeline create con TFX è tecnicamente un Directed Acyclic Graph (DAG), un termine molto fancy per indicare un grafico diretto senza cicli diretti.
Un altro termine ancora più complicato per esprimere in modo conciso una struttura tale per cui sia impossibile creare sequenze loop che da un vertice A ritornino al vertice A dopo un numero generico n di operazioni.
Questa accortezza è utile perché spesso nella documentazione le pipeline vengono indicate come DAGs.
Ora, devi sapere una cosa.
Una TFX Pipeline a questo punto non è altro che una sequenza di componenti che implementano una pipeline di machine learning.
TFX mette allora a tua disposizione una serie di componenti standard con cui assemblare la pipeline.
Vediamoli rapidamente.
Componenti TFX Standard
Una tipica pipeline include i seguenti componenti:
| Componente | Descrizione |
| ExampleGen | è il componente d’ingresso dei dati che supporta i formati CSV, tf.Record e BigQuery, con varianti custom per supportare Avro e Parquet. È comunque possibile crearne ad hoc per supportare pressoché tutti i formati compatibili con Apache Beam. |
| StatisticsGen | è il componente per generare feature statistics dai dati, che consuma il dataset generato da ExampleGen e emette quello aggiornato. |
| SchemaGen | crea un data schema a partire dalle feature statistics |
| ExampleValidator | cerca anomalie e dati mancanti |
| Transform | esegue operazioni di feature engineering |
| Trainer | allena il modello (operazione i training) |
| Tuner | regola gli iper-parametri (hyperparameter tuning) |
| Evaluator | esegue analisi approfondite sul modello e ti aiuta nella validazione, assicurandosi che siano validi per il rilascio in produzione |
| InfraValidator | verifica che il modello sia effettivamente servibile dall’infrastruttura |
| Pusher | rilascia il modello in produzione |
| BulkInferrer | esegue batch processing su un modello con richieste di inferenza prive di label |
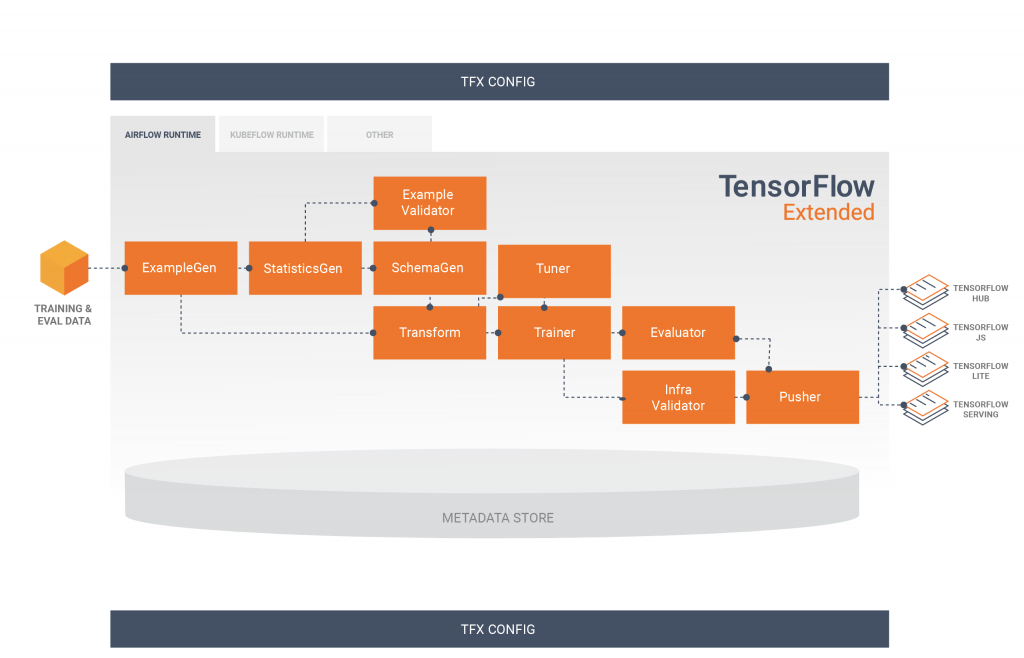
Il diagramma sottostante ti mostra una un esempio di flusso dati all’ interno della pipeline, con il dataset già diviso tra traning / evaluation in ingresso alla pipeline, e i diversi modelli in uscita compatibili con Tensorflow HUB, JS, Lite o Serving.
Ti faccio notare la strettura del diagramma, che come ti ho anticipato prima un Directed Acyclic Graph (DAG), con nessun loop possibile.
Librerie TFX
Quando abbiamo capito cos’è Tensorflow Extended ci siamo accorti della distinzione tra due elementi fondamentali: librerie e componenti.
Gli elementi interagiscono tra loro in una relazione che è ben spiegata dal diagramma qui sotto:
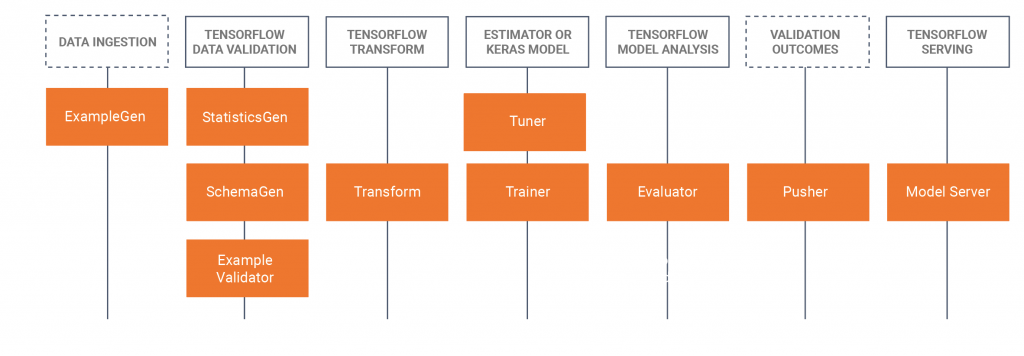
TFX fornisce dunque diversi pacchetti python che costituiscono le librerie usate per creare i componenti della pipeline, in modo che rispettino le esigenze del progetto che intendi portare a termine.
Le librerie incluse in TFX sono 6:
- TensorFlow Model Analysis (TFMA)
- TF Data Validation (TFDV)
- TensorFlow (TF)
- TensorFlow Transform (TFT)
- TFX Basic Shared Libraries (TFX-BSL)
- ML Metadata (MLMD)
TensorFlow Data Validation (TFDV)
Questa libreriadi TFX consente di analizzare e validare il dataset: contiene infatti una serie di strumenti e funzionalità per esplorare e correggere dati.
È progettata per essere altamente scalabile e lavorare in sinergia con Tensorflow e TFX.
TFDV include:
- Computazione efficiente di statistiche sommarie sui dataset
- Integrazione con Facets (i.e. Il tool open source di Data Visualization rilasciato da Google) per la visualizzazione di distribuzioni e altri insights
- Generazione automatica e visualizzazione efficace di schemi sui dati
- Identificazione e visualizzazione di anomalie (e.g. Feature mancanti, valori out-of-range, type errati)
TensorFlow Transform (TFT)
TFT è una libreria TFX per preprocessare dati con TensorFlow. Questa libreria può esserti utile per diversi scenari:
- Standardizzazione dei dati
- Conversione dati (i.e. Da stringhe a interi per la generazione di vocabolari, o da virgole mobili a interi e assegnazione a bucket basati sulla distribuzione)
Tensorflow
Chiaramente non serve presentazione per questa libreria. Tensorflow è usato per allenare modelli con TFX e creare come risultato un SavedModel.
Occhio che solo per il momento la piena compatibilità è limitata a TF 1.15, anche se TF 2.0 è pressoché interamente supportato (i.e. Ci sono alcune eccezioni)
TensorFlow Model Analysis (TFMA)
TFMA è la libreria di TFX che consente la validazione dei modelli.
Coadiuva TensorFlow per la creazione di un EvalSavedModel, la base su cui le analisi sono effettuate.
In pratica sei in grado di testare il modello attraverso grandi datset in modo distribuito, usando le stesse metriche definite in fase di allenamento.
Queste metriche possono essere calcolate su sezioni differenti di dati e poi visualizzate su Jupyter Notebooks.
TensorFlow Metadata (TFMD)
TFMD è la libreria di TFX che fornisce una rappresentazione per i metadata utile in fase di training del modello.
Il formato serializzato di metadata include:
- un schema che descrive i dati tabulari (e.g. tf.Examples)
- una collezione di statistiche sommarie sul dataset
ML Metadata (MLMD)
L’ultima libreria di TFX che ti presento consente di registrare e recuperare metadata associati a workflow di ML Developer e data scientist.
In pratica a ogni esecuzione di una pipeline in produzione genera metadata, con informazioni sui vari componenti, la loro esecuzione, e il risultato finale.
In caso di comportamenti anomali o errori, questi metadata consentono di analizzarne il funzionamento e correggere bug.
Considerali equivalenti ai file di log comuni, che puoi usare per rispondere a domande.
Per il momento è tutto.
Per aspera, ad astra.
Un caldo abbraccio, Andrea



