
Recurrent Neural Network è un classe di reti neurali artificiali impiegata in task di previsione, capace di analizzare Time Series e prevedere andamenti futuri: il prezzo delle azioni, la traiettoria di un veicolo, la nota successiva in una melodia e molto altro.
Generalizzando, la peculiarità delle Recurrent Neural Network è l’abilità di lavorare su sequenze di lunghezza arbitraria, superando le limitazioni in questo senso imposte da altre strutture, quali le Convolutional Neural Network (CNN) che impongono input di lunghezza fissa.
So bene che il tuo interesse è ampio, quindi ecco il link per approfondire le Convolutional Neural Networks.
Tornando a noi, così le Recurrent Neural Networks sono in grado di lavorare su:
- Frasi e frammenti di testi
- Audio
- Documenti
Consentendoci di risolvere problemi come:
- speech-to-text
- Sentiment Analysis (estrazione del sentimento da frasi, e.g recensioni e commenti social)
- automatic translation
In conclusione, rappresentano un validissimo asset da impiegare nei problemi di Natural Language Processing (NLP).
Dai un’occhiata qui, per altre applicazioni di NLP
Infine, l’abilità di anticipare propria delle Recurrent Neural Network le rende sorprendentemente creative.
Chiedendo loro d’individuare le note successive più probabili in una sequenza melodica è possibile dare vita a veri e propri spartiti musicali interamente redatti da Intelligenze Artificiali, come questa creata da Google’s Magenta Project usando Tensorflow, una libreria di cui abbiamo parlato in passato qui e qui.
Ti senti carico mio capitano? Ottimo!
Salpiamo a vele spiegate verso gli infiniti orizzonti, sotto l’egida di Zefiro.
Andiamo alla scoperta delle fondamenta sotto le Recursive Neural Networks, dei principali problemi da affrontare e le soluzioni ampiamente utilizzate per far fronte alle insidie comuni.
Recurrent Neural Network
Sappiamo che una rete neurale artificiale è costituita da unità base chiamate neuroni, neurons in inglese.
Fin’ora ci siamo limitati a studiare strutture ti tipo feedforward, in cui l’attivazione fluiva in una sola direzione: dall’input all’output layer.
Una Recurrent Neural Network è simile alle reti precedenti, fatta eccezione per la presenza di una connessione retrograda (connection pointing brackward).
Niente paura, esempio alla mano.
Per comprendere meglio questa struttura consideriamo l’esempio più semplice di RNN: un solo neurone che riceve un input, produce un output e lo invia indietro a se stesso (figura a sinistra).
A ogni time step (t), chiamato anche frame, il recurrent neuron riceve gli inputs x(t) e il suo stesso output dallo step precedente y(t–1) .
Rappresentiamo al meglio questa piccola rete in funzione del tempo con un metodo chiamato unrolling the network through time.
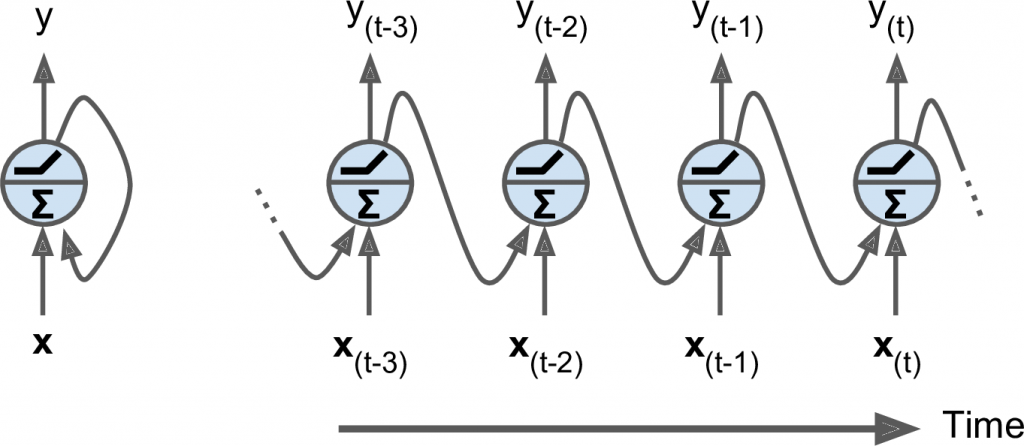
Ovviamente, possiamo creare facilmente un livello (layer) di neuroni ricorrenti. A ogni time step t, ciasun neurone riceve un input vector x(t) e l’ouput vector dal precedente time step y(t–1) .
Nota bene che stiamo ora parlando di vettori, quando prima gestivamo un solo scalare poiché prendevamo in considerazione un singolo neurone.
Matematica delle RNN
Ogni recurrent neuron elabora quindi due set di pesi (set of weights, or weight vectors):
- wx , per l’input x(t)
- wy , per l’output y(t–1) del precedente time step
Considerando l’intero recurrent layer, possiamo inserire i weight vectors in due weight matrices Wx e Wy. Aggiungendo il bias term b e la funzione di attivazione ϕ(·), una ReLU in questo caso, otteniamo la seguente formuale per il calcolo del vettore di output di un singolo livello della rete.
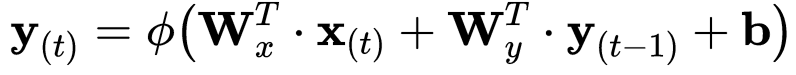
Come per le reti neurali feedforward, anche qui possiamo calcolare l’ouput in un unica operazione per un singolo mini-batch inserendo tutti gli input di un time step t in una matrici di input X(t)
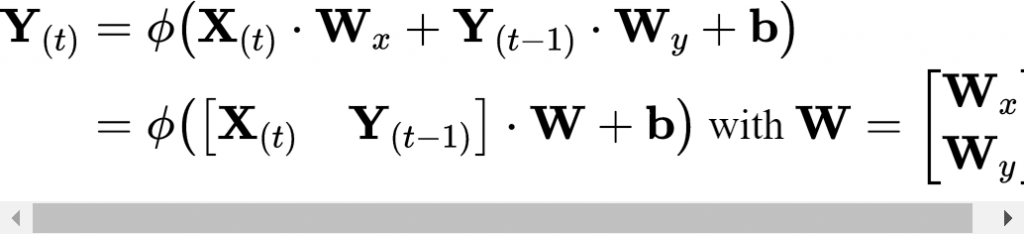
Un minimo di legenda:
- Y(t) è una m × nneuroni matrix contenente l’output layer al time step t per ciasun istanza nel mini-batch (m è il numero di istanze e n quello dei neuroni)
- X(t) è una matrice m × ninputs contenente tutti gli input delle istanze ( ninputs è il numero di input features)
- Wx è una matrice ninputs × nneurons contenente i weights per gli input del time step corrente
- Wy è una matrice nneurons × nneurons contenente i weights degli output del time step precedente
- b è un vettore di dimensioni nneurons contenente il bias term di ogni neruone.
- Le matrici di wieghts Wx and Wy sono spesso concatenate verticalmente in una singola matrice W di dimensioni (ninputs + nneurons) × nneurons
- La notazione [X(t) Y(t–1)] rappresenta una concatenazione orizzontale delle matrici X(t) e Y(t–1).
Memory Cells in Recurrent Neural Network
Considerando il fatto che l’ouput del recurrent neuron al time step t sia una funzione di tutti gli inut del precedente time step, possiamo considerare questo una forma di memoria.
Chiamiamo dunque una memory cell quella parte di rete neurale capace di preservare qualche stato nel tempo.
Un singolo neurone ricorrente, o uno strato di neuroni ricorrenti, è dunque una forma di basic cell.
In generale lo stato di una cell al time step t denotato da h(t), dove l’h indica hidden, è una funzione di:
- inputs a quel particolare time step
- il suo stato precedente
h(t) = f(h(t–1), x(t))
Per un solo recurrent neuron, l’output è equivalente allo stato stesso. Quando sono presenti molteplici neuroni, le cose si complicano.

Una recurrent neural network elabora una sequenza d’input producendone una di ouput simultaneamente, rendendole ideali ad esempio per prevedere l’andamento azionario di alcuni titoli, a partire da una serie storica.
Si tratta di una rete di tipo sequence to sequence, ma ce ne sono altre.
Vediamole assieme!
Recurrent Neural Network Structure Types
In base alla sequenza d’Input e quella di Output, possiamo distinguere diverse strutture per le Recurrent Neural Networks
Sequence to Sequence
Tornando all’esempio precedente per il calcolo del valore azionario, inseriamo i dati di N giorni, e calcoliamo la previsione dei prezzi slittati di un giorno del futuro: da N-1 a domani.
Sequence to Vector
Alternativamente, possiamo fornire alla rete una sequenza d’input, ignorando tutti gli output, a eccezione dell’ultimo.
Con questo sistema siamo in grado di generare modelli di sentiment analysis fornendo una recensione e ottenendo un’analisi di odio o amore (un sentiment score), sotto forma di vettore da -1 [hate] a +1 [love]
Vector to Sequence
Al contrario, possiamo inserire un singolo input al primo time step (e zero per quelli successivi) ottenendo comunque una sequenza di output per ogni time step.
Una struttura di questo tipo è particolarmente adatta a gestire un’immagine (vettore di dati) e produrre una didascalia (sequenza di parole e lettere).
Delayed sequence to sequence
Infine, possiamo avere una rete sequenze-to-vector chiamata Encoder seguita da vector-to-sequence chiamata Decoder.
Questa struttura di Recurrent Neural Network è utile per task di traduzione.
Inseriamo una frase in lingua, convertendola in una singola rappresentazione vettoriale attraverso l’Encoder per poi tradurla in un’altra lingua con l’ausilio del Decoder.
Questo modello chiamato Encoder-Decoder fornisce prestazioni migliori rispetto a uno di tipo sequence-to-sequence, poiché l’ultima lettera di una frase potrebbe influenzare la prima della traduzione.
Così dovremmo aspettarne l’intera elaborazione prima di procederne alla traduzione.

Sequence-to-vector (top-right)
vector-to-sequence (bottom-left)
Delayed sequence-to-sequence (bottom-right)
Con questo possiamo dire conclusa la nostra introduzione all’affascinante mondo delle Recurrent Neural Network. In attesa di elaborare qualche dimostrazione utile del loro funzionamento, penso tu possa trovare interessante altri articoli del blog!
Un caldo abbraccio, Andrea.



