
I Recommender Systems possono essere distinti attraverso l’ausilio di una tassonomia, vale a dire una serie di criteri che ne permettono la classificazione: ecco la Recommender Systems taxonomy!
Prima di procedere allo sviluppo di un reccomender system, è fondamentale raccogliere le necessità che un sistema simile debba soddisfare.
L’obiettivo di questo post è fornire dunque un framework per studiare e definire un sistema di raccomandazione, massimizzando la comunicazione tra aree di sviluppo, attraverso l’ausilio di un linguaggio tecnico chiaro e preciso.
Ti sembrano delle ottime premesse?
Tutto a dritta marinaio. La meta ci aspetta!
Recommender Systems taxonomy
Presentata dai professori Joseph A. Konstan e Michael D.
Ekstrand in “Introduction to Recommender Systems,”, la tassonomia sfrutta le seguenti dimensioni per descrivere un recommender system:
- dominio
- scopo
- contesto
- livello di personalizzazione
- whose opinions
- privacy
- attendibilità
- interfaccia
- algoritmi
Preparati a esplorare ogni dimensione al fine di arricchire il nostro lessico e affinare le conoscenze nel campo dei Recomender Systems.
Benissimo.
Inizia il viaggio.
Dominio (Domain)
La prima dimensione della Recommender Systems Taxonomy è definita dominio, o domain, e rappresenta la tipologia di contenuto che viene raccomandato.
Un esempio?
Subito!
Il dominio del sistema di raccomandazione in uso presso Netflix è costituito da film e serie TV.
Devi sapere che il domain può però essere qualsiasi cosa:
- il contenuto di una playlist
- offerte di lavoro
- libri
- auto
- vacanze
- destinazioni
- persone da incontrare
- plugin wordpress da disinstallare perché ti fanno girare i c** a forza di aggiornamenti che scatenano errori
Insomma, un po’ di tutto (Fuorché l’ultima. L’ultima proprio no)
Definire il dominio non solo è utile per comprendere cosa faremmo con una raccomandazione, ma anche per capire quanto sia pericoloso sbagliare.
Sai molto bene come questi sistemi siano ben lungi dall’essere perfetti: hanno una soglia di errore che deve sempre essere presa in considerazione.
Quanto ci possiamo permettere di sbagliare dunque?
Nel caso in cui stessimo raccomandando un medicinale a un paziente, capisci bene che il margine di errore deve essere molto limitato, poiché il rischio derivante da un consiglio errato è alto.
Al contrario, raccomandare musica è assai meno problematico: se sbagliassimo, potremmo al limite far scoprire a un utente un nuovo genere musicale!
Infine, il dominio ci fa capire se sia possibile raccomandare lo stesso elemento più volte, oppure no.
Scopo (Purpose)
Occorre definire lo scopo da due punti di vista:
- quello dell’utente finale
- quello del provider
Consideriamo Netflix, un provider di Film e Serie TV.
Il suo scopo è aumentare i guadagni della vendita di abbonamenti, fornendo agli iscritti contenuti che trovino interessanti.
Con un catalogo di oltre 10k elementi, questa apparentemente banale operazione rivela la sua complessità.
Possiamo aspettarci che l’utente medio spulci la lista alla ricerca del titolo perfetto per lui?
Certo che no! Entrambi sappiamo che questo sarebbe un suicidio per l’azienda.
Come facciamo quindi a tradurre questo problema in un linguaggio formale?
Brevissima digressione sul business world.
In ambito aziendale si usa un’espressione che condensa le performance dell’azienda in un punteggio, tendenzialmente definito dal settore in cui si opera, chiamato Key Performance Indicator (KPI).
Per una compagnia di assicurazioni è il Net Promoter Score (NPS), molto semplicemente la risposta alla domanda: “Quanto facilmente raccomanderesti il nostro prodotto a un amico?“
Saresti sorpreso di scoprire quanti milioni spendano queste aziende ogni anno in call center e attività di raccolta dati per intervistare clienti e definire questo punteggio.
Tornando a noi…
Il KPI di Netflix è rappresentato dal numero di ore che un utente trascorre sulla piattaforma: tanto più alto, quanto meglio l’azienda sta lavorando.
Proxy Goal
Tieni presente una cosa.
Quando prendiamo come riferimento un obiettivo diverso dal primario (direct goal), parliamo di Proxy Goal.
I Proxy Goal sono patate bollenti, quindi tieniti alla larga da loro.
Calma, nessuno abbandona un marinaio alla deriva.
L’uso di un Proxy Goal potrebbe condurti a misurare effetti diversi da quelli realmente importanti.
Più tempo sulla piattaforma dici?
Significa forse che gli utenti non riescono a trovare il film che tanto cercavano, gettandoli in uno stato di frustrazione, o che lo trovino ma il sito si blocchi.
Questi aspetti, facilmente ignorabili, risultano potenzialmente fatali, pur contenendo
Altra cosa fondamentale è il domain knowledge: vale a dire conoscere le regole del business in cui si opera.
Concetto che nell’esempio implica sapere che Netflix è obbligata a pagare un costo diverso per i diritti di alcune serie, o film, rispetto ad altre, e di conseguenza occorre pesare le raccomandazioni in accordo anche a regole economico aziendali specifiche.
Contesto (Context)
La terza dimensione che esaminiamo è definita contesto, l’ambiente nel quale l’utente riceve le raccomandazioni.
Ambiente inteso a 360°.
Riprendendo l’esempio, il context può essere il device fisico (smartphone, tablet, smart TV), la posizione geografica del dispositivo, l’orario della giornata e il comportamento dell’utente, a cui aggiungiamo il meteo e perché no l’umore dello user.
Nell’analisi di un corso di Coursera su Data Science e machine learning che abbiamo fatto qui, avevamo scoperto un SaaS chiamato Foursquare per la raccolta di dati utili anche a sistemi di raccomandazione. Lo vedremo prossimamente.
Livello di Personalizzazzione
La raccomandazione di un recommender system è contraddistinta da un livello di personalizzazione (personalization level) discreto, che possiamo codificare in tre valori:
- Non personalized (e.g. I film più visti in Italia)
- Semi-personalized (e.g. Film d’azione che potresti vedere)
- Personalized (e.g. Questi film potrebbero piacerti)
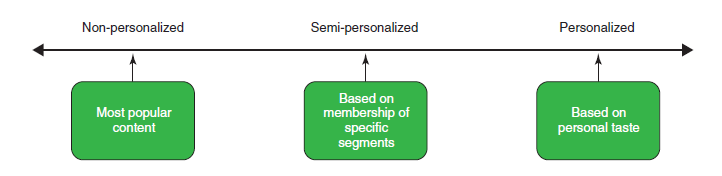
Avremo modo di approfondire le caratteristiche di ognuno in un altro post.
Whose opinions
È una dimensione oggi poco utilizzata, ereditata da un passato in cui le raccomandazioni erano fornite da esperti che manualmente provvedevano ai consigli.
Oggi, quasi tutti i sistemi online fanno riferimento alle masse. Ho trovato comunque opportuno riportarlo, per completezza d’informazione.
Privacy e attendibilità (trustworthiness)
Come certamente saprai, in questo blog prendiamo molto seriamente i discorsi su privacy e sicurezza dei sistemi di machine learning.
Stiamo maneggiando dati di alto valore: informazioni personali, che devono essere preservate.
Occorre quindi prendere le dovute precauzioni onde evitare la diffusione di dati sensibili.
Discorso a parte, non per questo meno importante, sull’attendibilità.
Gli utenti odiano le pubblicità invadenti e sarebbero persino disposti a pagare per ricevere consigli utili.
Pausa di riflessione su eventuali mercati che potremmo conquistare… …e torniamo a noi!
Però la vita è un equilibrio di verità e percezione.
Un buon sistema di raccomandazione deve infondere nell’utente fiducia, proponendogli consigli appropriati.
La dimensione di trustworthiness indica quanto l’utente si fidi delle raccomandazioni ricevute, l’attendibilità del recommender system.
L’obiettivo è chiaramente quello di evitare che le ignori considerandole manipolatrici, alla stregua di pubblicità invadenti.
Interfaccia (Interface)
Questa dimensione della Recommender Systems Taxonomy raffigura la tipologia di input / output che il sistema produce.
Lo approfondiamo un prossimo post, poiché ci sono diversi concetti che meritano la giusta attenzione.
Algoritmi (Algorithms)
Quest’ultima dimensione della Recommender Systems Taxonomy, fa riferimento all’implementazione del sistema.
Distinguiamo gli algoritmi in due gruppi in base alla natura dei dati che necessitano:
- Algoritmi che dipendono dai dati di utilizzo di una piattaforma, e che vengono chiamati di collaborative filtering
- Algoritmi che usano dati dei prodotti e caratteristiche utente, e che vengono definiti di content–based filtering.
Esiste poi un terzo gruppo che ne consegue, nato dalla loro intersezione: sono gli hybrid recommender systems.
Li abbiamo analizzati a fondo in questo post.
Recommender Systems Taxonomy: conclusione
Questo post si è rivelato particolarmente lungo, anche se certamente ricco d’informazioni interessanti.
Prima di lasciarti con il tradizionale saluto, intendo condividere con te un’ultima riflessione.
Abbiamo speso centinaia di parole solamente per descrivere le caratteristiche di alto livello di un sistema di raccomandazione, e appena grattato la superficie.
Addentrarsi a livello di algoritmi, piattaforme di rilascio in produzione, sistemi di monitoraggio delle prestazioni e molto altro richiederebbe diversi post.
Questo per darti un’idea di quanto questi argomenti siano effettivamente densi d’informazione e perché richiedano tempo per sedimentarsi in noi.
Un momento, ma noi non abbiamo limiti… Allora procediamo in questa avventura, un passo alla volta, sempre più nel dettaglio!
P. S. Le informazioni per la scrittura di questo post provengono da un libro che sto leggendo. Trovi il link qui.
Per il momento è tutto!
Un caldo abbraccio, Andrea.



