
Project MELLODDY (MachinE Learning Ledger Orchestration for Drug DiscoverY) è l’ambizioso obiettivo di aumentare l’efficienza nella scoperta di nuovi farmaci (drug discovey).
Intende raggiungerlo migliorando l’accuratezza dei modelli predittivi., attraverso l’ausilio della più grande collezione dati su piccole molecole con attività cellulare o biochimica nota.
Seguimi, perché questo progetto è davvero affascinante!
Ciò che rende ancora più intrigante il Project MELLODDY è l’architettura impiegata.
L’allenamento avviene infatti su una rete dati decentralizzata di 10 aziende farmaceutiche, senza alcuna esposizione di dati proprietari (i.e. Tutelando la proprietà intellettuale).
Andiamo allora alla scoperta delle specifiche del Project MELLODDY!
Continua a leggere.
D’ora in avanti useremo alcuni termini tecnici, quindi una ripassata agli argomenti può tornare utile.
Qui abbiamo chiarito cosa sia il Cross-Silo Federated Learning mentre qua abbiamo presentato il federated learning.
Ora che ci siamo rinfrescati la mente, possiamo procedere.
Project MELLODDY: why?
Le aziende farmaceutiche, come molte altre realtà, hanno evitato in passato di condividere dati privati per timore di compromettere la proprietà intellettuale e far guadagnare terreno ai competitors.
La condivisione dati, specie in un mondo sempre più caratterizzato dall’AI, ha però i suoi vantaggi.
I laboratori di ricerca potrebbero senz’altro accelerare il processo di ricerca e sviluppo dei nuovi farmaci, sfruttando lo shared knowledge.
Potremmo così ridurre i costi di trattamento e aumentare il tasso di successo nella scoperta di candidati ideali.
Facciamoci poi un’idea dei numeri del settore.
Portare un nuovo farmaco sul mercato richiede in media 13 anni e un investimento di 2 miliardi di dollari.
Sforza la tua mente da analista esperto a evitare di analizzare la frase chiedendoti quale sia la deviazione standard della distribuzione, e quanti degli investimenti si rivelino buchi nell’acqua.
Possiamo allora andare oltre.
Il Project MELLODDY intende eliminare il compromesso tra condivisione dati e sicurezza, riducendo i costi e aumentando i profitti.
Grazie alla partnership con NVIDIA, un’infrastruttura cloud con potenti GPU è stata messa a disposizione delle aziende per allenare modelli di AI con un approccio federato a tutela dell’IP (Intellectual Property).
Caratteristiche generali
Project MELLODDY è progetto europeo, della durata di tre anni, che prevede la cooperazione di aziende pubbliche e private.
Mathieu Galtier, il coordinatore del progetto, spiega che:
L’obiettivo è quello di sfruttare la conoscenza collettiva del consorzio realizzando una piattaforma che contenga, tra gli altri, algoritmi di apprendimento automatico multi-task, incorporando un esteso sistema di gestione della privacy, per identificare i composti più efficaci per lo sviluppo di farmaci, proteggendo i diritti di proprietà intellettuale dei collaboratori del consorzio.
Mathieu Galtier, Project Coordinator, Owkin (Tradotto)
Ormai è chiaro quale sia l’obiettivo primario, ma non finisce qui.
Ricordi la corsa allo spazio, degli anni 60 e 70 del secolo scorso?
Bene.
Sappi che fece registrare uno sviluppo tecnologico esponenziale, allo stesso modo il Project MELLODDY intende aprire la strada all’applicazione su vasta scala delle Privacy Enhancing Technologies (PETs).
Vogliamo infatti superare i limiti imposti dalle attuali soluzioni di machine learning e dimostrare la validità delle ipotesi:
- Il Machine Learning su diversi data type e partner è possibile senza perdite inaccettabili d’informazioni private.
- È possibile creare un framework scalabile, flessibile e sicuro per il Privacy Preserving Federated Learning
- È possibile validare il modello su un volume storico di dati rilevanti senza precedenti.
Abbiamo esaminato rapidamente le caratteristiche generali del progetto e possiamo ora dare uno sguardo a quelle tecniche.
Seguimi!
Non temere: spiegheremo ogni termine e lo renderemo comprensibile così da agevolare la lettura e alleviare il tedio.
Caratteristiche tecniche
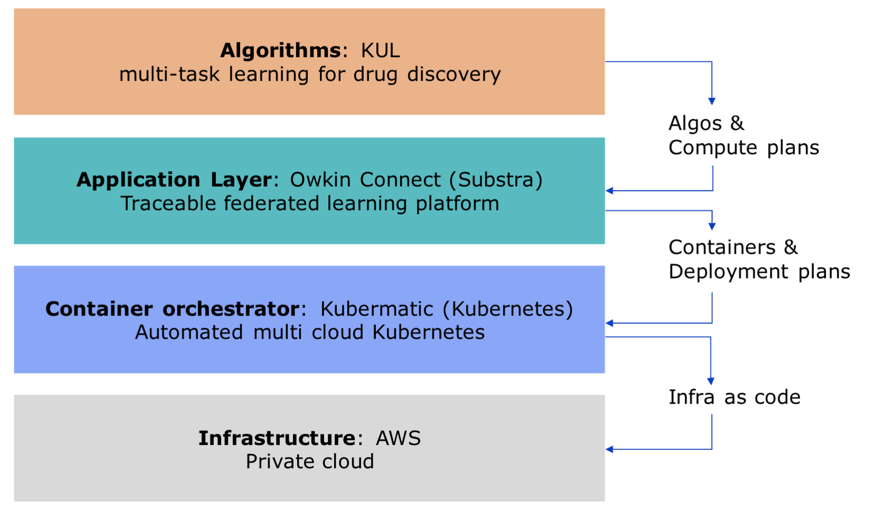
Orchestrare una collaborazione tra 17 diversi partner (insieme di cui fanno parte le 10 aziende farmaceutiche) è certamente un lavoro Impegnativo.
Un set di piattaforme di prim’ordine rende possibile la comunicazione e lo sviluppo senza soluzione di continuità.
Alcune di queste sono:
- Box: per la condivisione sicura di documenti
- Monday: per la pianificazione e gestione condivisa dei task
- GitLab: lo storage del codice.
- Slack: per la discussione rapida e organizzata.
A questo link puoi trovare molti altri dettagli, tanto interessanti, sull’organizzazione di un progetto di simili dimensioni.
Per quanto riguarda la parte software, Owkin Lab è la startup incaricata dello sviluppo della piattaforma federata.
La piattaforma Owkin Loop connette i ricercatori con i dataset di più alta qualità da tutto il mondo. I suoi componenti principali sono due:
- Owkin Studio, una piattaforma user-friendly per l’applicazione dell’Intelligenza Artificiale alle coorti di ricerca e domande scientifiche.
- Owkin Connect, il subsrato software per l’allenamento sicuro e federato dei modelli.
Il dataset farmaceutico su cui il modello finale intende essere allenato, è uno storico d’informazioni su differenti composti chimici e loro attributi.
Attraverso l’interfaccia del Project MELLODDY i ricercatori sono in grado di effettuare query private e anonime su specifici composti.
La query è successivamente inviata a ogni data repository dei partner per identificare un’eventuale corrispondenza.
I dati non lasciano mai l’azienda che li ha generati e quindi la proprietà intellettuale è preservata, limitando al minimo il rischio di data leak.
Inoltre, il Project MELLODDY sfrutta un così definito Blockchain Ledger System, un sistema attraverso cui ogni operazione effettuata è salvata irreversibilmente su una rete, anch’essa distribuita, che consente il massimo controllo delle aziende sui propri dati.
Approfondimenti sul Project MELLODDY
Chiaramente questo post non può che essere un’introduzione al progetto.
Per approfondire ho quindi raccolto per te alcune fonti che potrai trovare illuminanti.
Qui trovi la descrizione tecnica da parte di NVIDIA.
Questo è invece il sito ufficiale del Project MELLODDY
Per il momento è tutto.
Per aspera, ad astra.
Un caldo abbraccio, Andrea.



