
Il Privacy Preserving Record Linkage è l’operazione d’identificazione, abbinamento (matching) e fusione (merging) di record appartenenti alla stessa entità e provenienti da differenti, o dal medesimo, database. Il tutto avviene senza tuttavia rivelare alcuna informazione privata delle parti coinvolte.
Esistono molteplici espressioni che riconducono alla medesima pratica.
Devi infatti sapere che il Record Linkage è conosciuto anche come:
- Data Matching
- Data Linkage
- Entity Resolutions
- Object identification
- Field Matching
I due scopi principali dell’applicazione di questo processo sono:
- Quello di data integration, per la creazione di un unico file e successive analisi sui dati integrati
- Quello di step intermedio per la creazione di un file su cui eseguire calcoli futuri.
Con il crescente interesse per soluzioni di Privacy Preserving e il costante aumento del volume dei dati in gioco, ecco la nascita del Privacy Preserving Record Linkage.
Facciamo una breve riflessione.
Big Data e Privacy
I Big Data rappresentano enormi opportunità per le aziende intente a sviluppare una filosofia data-driven volta a un costante miglioramento dei propri prodotti.
Non solo.
Cercando esempi specifici, il settore dell’ healthcare potrebbe trarre enormi benefici attraverso la condivisione dei dati ospedalieri, accelerando le ricerche e velocizzando le diagnosi.
Il principale ostacolo è però rappresentato dalla necessità di tutelare la privacy delle istanze coinvolte nelle operazioni di condivisione e analisi.
A livello corporate, questo limita sia l’interazione interaziendale, sia quella intraziendale, qualora i dati fossero contenuti in data silos di singoli dipartimenti o team.
Il Privacy Preserving Record Linkage è allora una valida soluzione a queste problematiche.
Dobbiamo però considerare che l’applicazione del Record Linkage ai Big Data ha fatto emergere alcune sfide:
- Problemi di scalabilità, da imputarsi principalmente al volume di dati generato dalle ingenti dimensioni di database multipli
- Mediocri risultati, dovuti alla Variabilità (varierty) e Veridicità (veracity) dei dati (i.e. Dati provenienti da diverse fonti, in altrettanti formati, e contenenti bias e anomalie)
Record Linkage
Prima di concentrarci sui meccanismi di tutela della privacy è opportuno chiarire il funzionamento, seppur in modo approssimativo, del processo di Record Linkage.
Devi allora conoscere un concetto chiave.
La maggior parte delle tecniche moderne di Record Linkage fa ricorso a un approccio probabilistico noto come metodo di Fellegi-Sunter, basato su un modello decisionale.
Questo metodo è raccomandato nei casi in cui manchino unique identifiers per ogni record, o quelli presenti siano affetti da errori.
Della serie… se su due dataset in fase di raccolta dati è stato previsto un ID comune ben venga: possiamo unire i record. In caso contrario, ci occorre una strategia.
Nello specifico dobbiamo presupporre che, affinché il metodo di Fellegi-Sunter possa essere applicato:
- I record delle data sources descrivano osservazioni di entità appartenenti a una popolazione particolare.
- I record contengano alcuni attributi identificanti entità individuali (e.g. Nome, indirizzo, età per persone fisiche, o turnover, numero d’impiegati per le aziende).
Sulla base di queste premesse, date due o più fonti dati, le coppie determinate dal prodotto cartesiano (Cartesian product) delle data sources devono essere classificate in tre gruppi indipendenti e mutualmente esclusivi (mutually exclusive):
- Gruppo di corrispondenze (set of matches)
- Gruppo di non corrispodenze (set of non-matches)
- Insieme da controllare manualmente
Ora compariamo gli attributi simili generando un punteggio probabilistico di appartenenza di ogni coppia a ciascun gruppo.
Il modello mira a minimizzare sia l’errore di classificazione che la probabilità che una data coppia appartenga all’insieme di controllo manuale.
Su questo documento, peraltro curato dalla comunità europea, possiamo trovare maggiori informazioni a riguardo.
Privacy Preserving Record Linkage
Eviteremo di scendere troppo in particolari tecnici per almeno tre ragioni:
- La natura divulgativa del post, che non intende trattare formule matematiche complesse bensì fornire una overview generale sul processo.
- La complessità dell’argomento, per cui ho trovato fonti valide ma molto prolisse.
- Le particolari applicazioni del Record Linkage che lo rendono difficilmente utile in contesti comuni.
Ho comunque scelto di presentarti uno spunto utile su cui ragionare.
Anonlink è una suite di tecnologie ideata dall’azienda australiana Data61 che consente a due organizzazioni di eseguire il processo di Privacy Preserving Record Linkage, senza dunque far trapelare in alcun momento qualsivoglia PII (Personally Identifiable Information).
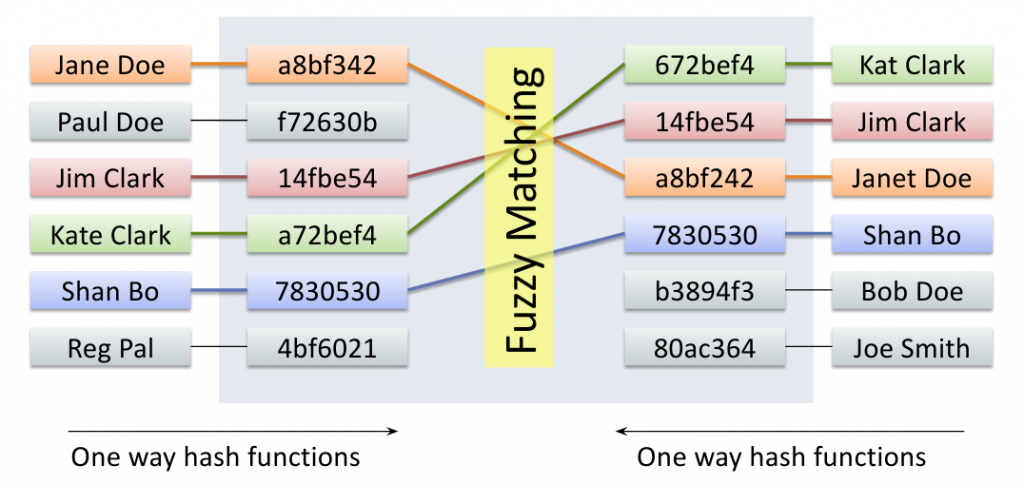
Utilizzando il client Anonlink, peraltro open source, è possibile creare dei linking code criptati, anche a partire da informazioni private, e inviarli a un servizio centrale che ne esegue l’entity resolution restituendo l’eventuale collegamento esistente.
A sovraintendere la procedura di matching è in questo caso una tecnica probabilistica, che calcola la similarità (similarity score) per ogni coppia di associazioni plausibili offrendo all’utente finale la possibilità di scegliere tra il risultato raw e l’accoppiamento migliore definito da un threshold.
In questo modo è persino possibile gestire il tradeoff tra precisione e accuratezza
Per il momento è tutto!
Un caldo abbraccio, Andrea.



