
Il Private Aggregation of Teacher Ensebles, meglio conosciuto come PATE framework, è un metodo di differential privacy che garantisce la privacy dei sample usati nel processo di training.
Mi conosci: detesto farti procedere nel vuoto.
Questo articolo sarebbe inutile se mi limitassi a fornire una minima definizione.
Preferisco invece accompagnarti in un viaggio alla volta della suprema conoscenza. A bordo del nostro amato veliero, tra considerazioni e riflessioni, sapendo che la meta è impossibile da raggiungere, ma che nel viaggio risiede il grande tesoro nascosto.
Allora ti chiedo…
Con l’albeggiare del sole, issiamo le vele per un nuovo giorno di navigazione: oggi scopriamo il PATE Framework.
Prima occorre però pulire quelle cime: elimina la salsedine ripassando il concetto di Differential Privacy, prendi questo.
Ottimo.
Procediamo.
Perché è utile il PATE framework?
Rispondiamo a questa fondamentale domanda in modo intuitivo!
Creiamo cioè le fondamenta su cui costruire il nostro ragionamento.
Consideriamo due differenti classificatori, allenati su altrettanti dataset indipendenti, cioè senza istanze in comune.
Qualora entrambi fornissero la stessa previsione su un medesimo input potremmo dire che nessuna informazione sugli esempi sia trapelata.
Infatti, la particolare configurazione e il risultato prodotto ci permettono di dire che la previsione sarebbe la stessa con e senza una qualsiasi osservazione dei due dataset.
Per il momento i risultati sono concordi.
Siamo felici perché la privacy è preservata, e pubblichiamo il risultato al mondo certi di non mettere a repentaglio alcun PII (Personally Identifiable Information)!
Un momento… Cosa facciamo se i risultati divergessero?
Perché devi rovinare la festa?
Comunque, hai perfettamente ragione!
Dapprima, cerchiamo di capire cosa significhi che i risultati siano diversi.
Abbiamo due label differenti che non possono essere rese pubbliche, poiché ognuna delle classi predette potrebbe diffondere informazioni private contenute nel rispettivo dataset di training.
Consideriamo un paziente fittizio, di nome Jane Smith, i cui dati contribuiscano alla creazione di uno solo dei due modelli.
Qualora questo stesso modello classificasse un paziente dalla cartella clinica simile a Jane come malato, e avessimo un risultato contrario fornito dal secondo, potremmo affermare che le informazioni private di Jane siano a rischio.
Ora che abbiamo chiarito l’area in cui ci troviamo a operare, chiariamo il funzionamento del PATE Framework.
Come funziona il PATE framework?
Le considerazioni che abbiamo sin’ora fatto ci consentono finalmente di capire in che modo il PATE Framework possa apprendere responsabilmente dai dati.
Iniziamo con il partizionare il nostro dataset originario in data subset.
Trattandosi di partizioni, per ogni coppia possibile di subset non ci sono dati in comune.
Alleniamo ora un modello, chiamato teacher, su ogni partizione.
Devi sapere una cosa fondamentale.
Uno dei grandi vantaggi del PATE Framework è non porre alcuna restrizione sull’operazione di training. Per usare un’espressione tecnica, è agnostico all’algoritmo di learning usato per la creazione dei teacher.
A questo punto ognuno dei teacher assolve al medesimo task di machine learning.
Possiamo anche affermare che uno solo dei teacher abbia esaminato i dati privati di Jane Smith.
Lo so che il tuo cervello preferisce le immagini!
Ecco per te una semplice illustrazione:
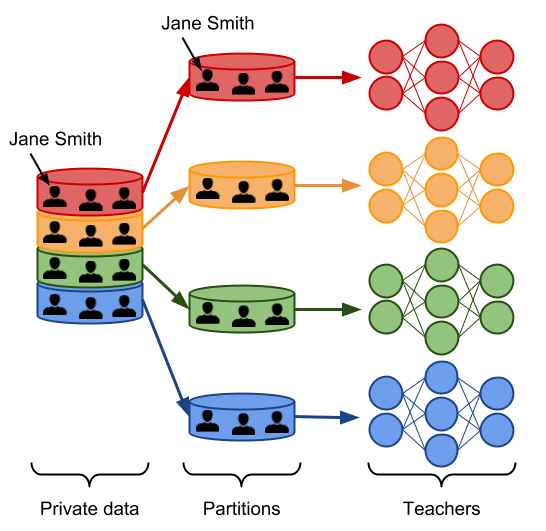
Abbiamo ora un insieme di modelli (ensemble of teacher models) allenati in modo indipendente, ma senza alcuna garanzia di tutela della privacy (guarantees of privacy).
Perché? Dimmelo te!
Perché la classe predetta da ciascun modello potrebbe far trasparire informazioni private delle relative istanze di training.
Random Noise
Il problema che ora ci poniamo è quello di sfruttare questo insieme di modelli per fare previsioni che rispettino la privacy delle osservazioni.
Il PATE Framework ci ascolta. Viene in contro alle nostre esigenze proponendoci di aggregare le previsioni individuali in una sola comune, aggiungendo nel mentre rumore (noise).
Come?
Il PATE Framework ci chiede di contare il numero di teacher che concordano sullo stesso vote (i.e. Producono come previsione la stessa classe), e perturbare questo conteggio facendo ricorso al Report Noisy Max (RNM) algorithm.
Il funzionamento di questo algoritmo richiederebbe un post separato e per il momento ci limitiamo a dire che aggiungiamo del rumore campionato da una distribuzione Laplaciana o Gaussiana.
Ecco il noisymax mechanism.
Quando due classi ricevono un equo (o quasi equo) numero di voti dai teacher, l’aggiunta del rumore casuale fa si che soltanto una sia quella effettivamente scelta come definitiva.
Possiamo anche considerare l’ipotesi che la maggior parte dei teacher concordi su un’unica classe. In questo caso l’aggiunta del rumore non altera l’esito della previsione finale.
Questa delicata orchestrazione garantisce al contempo privacy e correttezza previsionale, proprio grazie al noisy aggregation mechanism che abbiamo appena visto.
PATE Framework Example
Il nostro esempio avrà due versioni.
Jane è sana
La figura sottostante illustra il funzionamento descritto poco fa considerando la nostra amica Jane (mi pare un nome femminile, anche se non essendo un esperto di antroponimia potrei sbagliarmi) sana, e ipotizza che il consenso dei modelli sia sufficientemente alto.
In questo caso l’aggiunta del rumore casuale al conteggio dei voti, come richiesto dall’ aggregation mechanism, non altera la classe predetta.
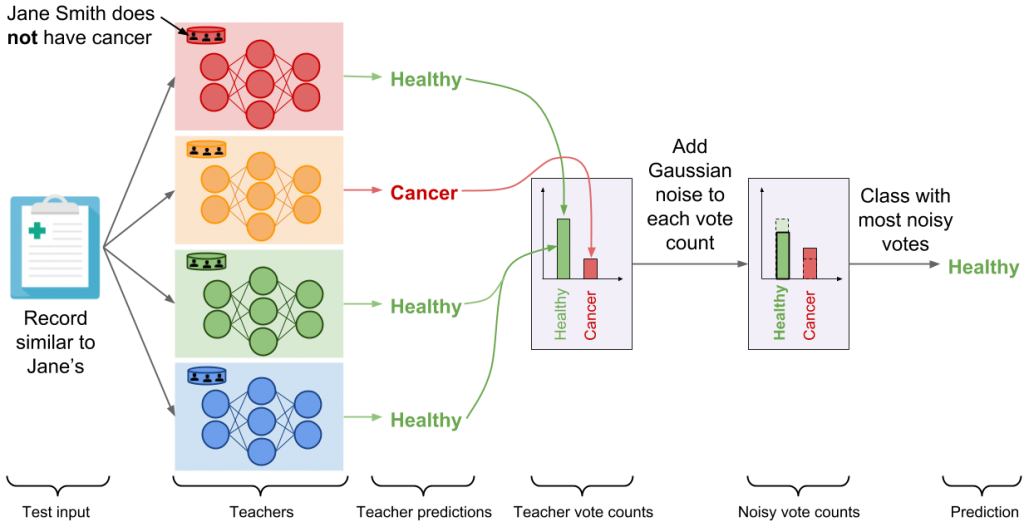
Per chiarezza, stiamo considerando un esempio semplice: l’aggregazione di un task di previsioni mediche binarie.
Sappi comunque che il PATE Framework è scalabile, come presentato da Papernot Et al. in questo articolo accademico, e possiamo quindi estenderlo anche a classificatori multiclasse.
Analizziamo ora lo spiacevole caso in cui la nostra amica Jane sia malata.
Jane è malata
Presta la massima attenzione: qui entra in gioco la potenza di questo metodo.
Il modello rosso, l’unico teacher allenato sulla partizione contenente le PII di Jane, ha imparato che un record simile a quello della nostra amica debba essere classificato come malato.
Il nostro esempio si configura pertanto come segue: due teacher hanno votato la label positiva e i restanti quella negativa.
Voti contati, e siamo in una situazione di equità.
In questa casistica l’aggiunta del rumore casuale (random noise) a entrambi i conteggi impedisce all’aggregazione di riflettere i singoli voti dei modelli teacher, proteggendo in ultima analisi la privacy finale di ogni record, Jane inclusa.
Data la presenza di un evento casuale, possiamo solamente teorizzare i due esiti possibili:
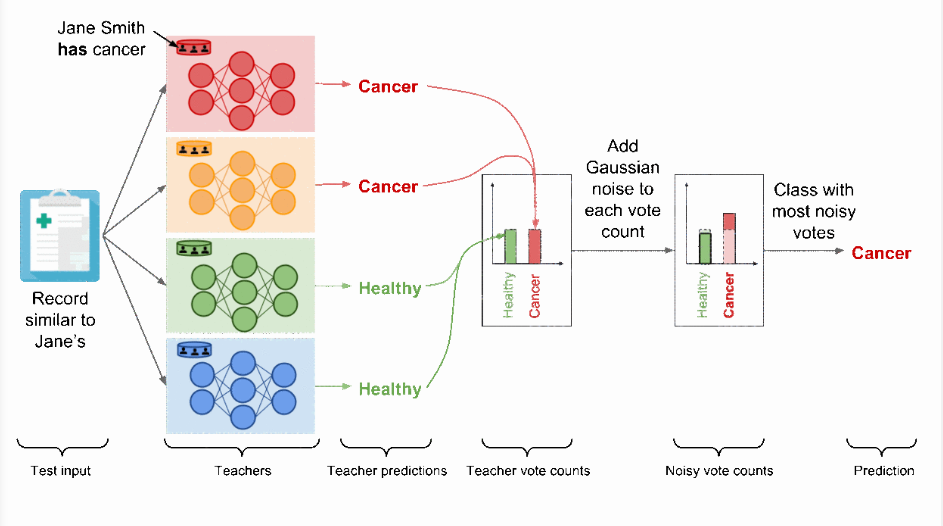
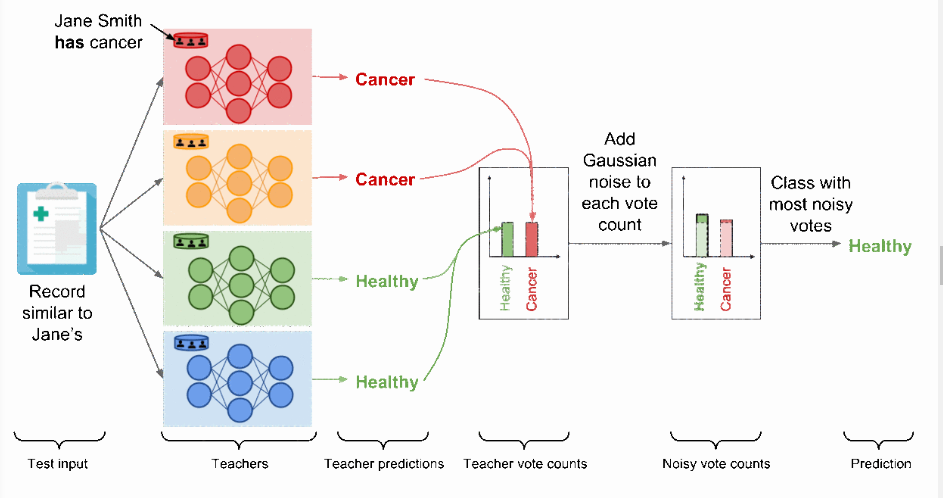
A questo punto il PATE Framework può essere pensato come una differentially private API: ciascuna label predetta dal meccanismo di aggregazione con rumore (noisy aggregation mechanism) ha rigorose garanzie di privacy differenziale (rigorous differential privacy guarantees), che limitano il privacy budget speso per attribuire la label a quell’input.
Privacy Budget
Il privacy budget è nuovamente un concetto che meriterebbe spazio a sé.
Semplifichiamo la questione per estrarre ciò di cui abbiamo realmente bisogno.
Utilizzando un effettivo rumore casuale (random noise) nella perturbazione dei dati, per raggiungere così la loro anonimizzazione, c’è un inconveniente che dobbiamo tenere a mente.
Ogni volta che effettuiamo una query su quei dati riduciamo il loro livello di anonimizzazione.
Questo perché potremmo potenzialmente aggregare i risultati e filtrare il rumore, considerando il valore medio, ripristinando il dato originale e compromettendo la privacy delle istanze.
Intendo evitare la discesa in scomodi dettagli tecnici.
Possiamo allora dire che il privacy budget è la metrica attraverso cui misuriamo indirettamente l’ammontare d’informazione potenzialmente trapelabile con garanzia di privacy.
In altri termini, il suo esaurimento costituisce il limite oltre il quale la privacy delle istanze non è più garantita.
Sarò onesto con te.
Questa definizione non è precisa, e contiene delle omissioni, anche se è più che utile per capire una questione legata al PATE Framework.
Tornando al nostro gioco di professori e voti, dobbiamo infatti fare alcune considerazioni.
Quando il consenso tra i teacher è elevato, il PATE Framework favorisce un basso valore di privacy budget e di conseguenza grandi garanzie di privacy.
Ora però arrivano 2 limitazioni.
- Primo, ogni previsione compiuta attraverso l’agregation mechanism aumenta il privacy budget totale. In altri termini, il privacy budget può potenzialmente diventare così elevato da rendere insignificanti le garanzie di privacy.
- Secondo, non possiamo rendere pubblici l‘insieme dei modelli professore (ensemble of techer models), poiché un aggressore potrebbe ispezionare i parametri interni e desumere informazioni sui dati privati di training.
Per queste ragioni il PATE Framework suggerisce un secondo, geniale, livello di garanzia: allenare un modello studente.
In questo modo aggiungiamo un ulteriore strato di astrazione tra l’utente finale, di buone o cattive intenzioni, e i dati.
Student Model
Lo studente è allenato trasferendo la conoscenza appresa dall’ insieme di professori con un sistema che preserva la privacy, ovviamente.
Partiamo da un unlabeled public dataset e inviamo le istanze all’ensemble of teacher per produrre le label di cui abbiamo bisogno.
Il noisy aggregation mechanism risponde con le private label, che possono ora essere usate per allenare il modello studente.
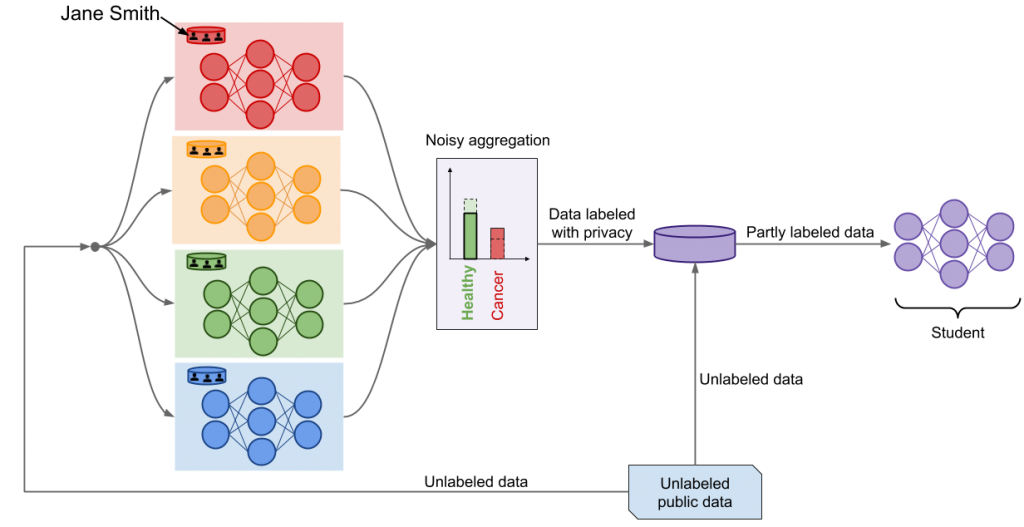
Lo student model, prodotto finale del PATE Framework, può finalmente essere rilasciato in produzione e rispondere a qualsiasi prediction query dell’utente.
I dati privati e i modelli professore sono ora superflui, poiché lo student model è l’unico impiegato per l’inferenza.
I problemi legati al privacy budget, sopra esaminati, sono ora risolti.
- Primo, il privacy budget complessivo è fissato a un valore costante, terminato il training dello student model.
- Secondo, un aggressore avente accesso ai parametri interni del modello studente potrebbe al massimo ricostruire i sui dati di training, che essendo pubblici, non minano in alcun modo la privacy.
Approfondimenti sul PATE Framework
Per maggiori approfondimenti, il nostro amico nonché geniale mente ideatrice delle GAN, Ian Godfellow, ha preparato per noi una superba presentazione del PATE Framework che puoi trovare a questo link.
Prima di salutarti, intendo condividere con te alcune ultime considerazioni.
I teacher possono essere allenati su dati privati e sensibili, mentre agli student devono necessariamente essere forniti dataset di training pubblici.
Sappiamo comunque che questi dati non debbano essere labeled e questo agevola il loro ottenimento, facilitandone la raccolta.
Inoltre, qualora un eventuale dataset pubblico non venisse individuato, si potrebbe far ricorso a un’operazione di pre-training su comparable dataset.
Concludo questo lungo post con alcuni link che potresti trovare utili:
- Making PATE bidirectionalally private
- PATE Analysis on COVID data (& relative study)
- Comic illustration on PATE
Un caldo abbraccio, Andrea.



