
La Non-IID ness è un’espressione usata in modo ampio per indicare il complesso di metodologie, algoritmi e approcci per rappresentare, modellare e capire quelle tipologie di dati che definiamo non-independently and identically distributed data.
Sarò sincero con te: la traduzione italiana qui crea un pasticcio.
Quello che all’apparenza è un post noioso, può rivelarsi di fondamentale importanza nel nostro studio sui sistemi federati e non solo.
Quindi, armiamoci di pazienza e una buona dose di un alcaloide a scheletro purinico: la caffeina andrà bene.
Ora.
Gli inglesi hanno un’espressione per indicare una descrizione priva di senso o resa incomprensibile da un eccessivo uso di termini tecnici: è gobbledygook.
Evitiamo di rendere questo post molto gobbledygook.
Devo però informarti di una pratica comune.
Tendenzialmente, nei progetti di machine learning compiamo un’assunzione sui dati (modelling assumption) trattandoli come se fossero indipendentemente tratti dalla una distribuzione comune.
Tecnicamente, ipotizziamo che i dati siano indipendenti e distribuiti in modo identico (independently and identically distributed, o IID).
Non sono completamente convito che l’ipotesi sia sui dati, anziché sulla loro distribuzione. Prendi quindi queste informazioni con le pinze, anche se si tratta di tecnicismi, e comunque guarda qui per maggiori dettagli.
Il mondo è però diverso dalla tanto perfetta teoria dei libri.
Capita così che i dati all’interno delle aziende siano distribuiti su differenti silos.
Il fatto non costituisce un problema fintantoché le analisi siano compiute sui singoli dataset.
Lo diventa in un contento interaziendale, o quando i dati sono distribuiti e quindi generati in situazioni molto differenti. In questi casi possono esistere variazioni significative nella distribuzione degli stessi sui diversi devices o locations.
I dati sono, ancora una volta tecnicamente, non-IID, e questo può portare a cali di performance per i nostri normali algoritmi, come chiaramente (più o meno) spiegato in questo articolo accademico.
Capiamoci meglio.
Non-IID | Case Study
Riduciamo il problema a un toy example.
Immaginiamo un gruppo di sette amici in visita allo zoo.
Il gruppo decide di creare un modello di machine learning per classificare l’animare ritratto in una foto.
Iniziano quindi a raccogliere i dati per la fase di training, scattando foto a ciascuno dei dici animai presenti, raccogliendo il risultato in un server centrale (dataset centralizzato).
In questo esempio fittizio, i sette amici raccolgono complessivamente 1307 foto dei dieci animali, definendo una media di circa 130 immagini per animale e una deviazione standard di circa 30.
Graficamente:
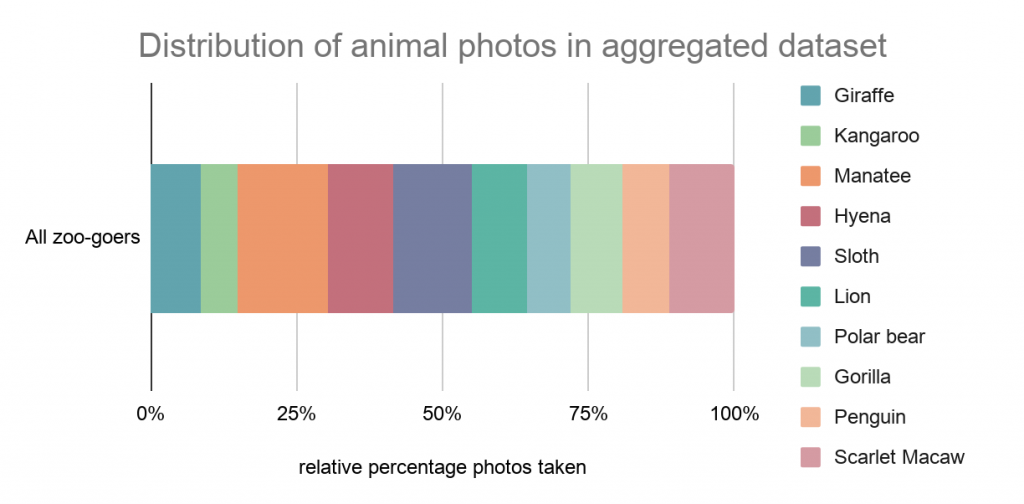
Gli amici organizzano i dati in una matrice di due colonne:
- valori RGB delle immagini
- label dell’animale
Attraverso l’ausilio di un pacchetto per Machine Learning open source, mescolano casualmente i dati dividendoli in tre gruppi:
- 80% per il dataset di training
- 10% per quello di validation
- 10% per quello di testing
Allenano quindi un modello usando l’algoritmo di Stochastic Gradient Descent come ottimizzatore e valutano le performance sul validation set per ogni ciclo di allenamento: in poco tempo il loro modello converge.
Gli amici si chiedono ora se sia possibile allenare un modello per lo stesso compito senza dover aggregare i dati raccolti in un unico dataset centralizzato.
Per completare il task, fanno ricorso all’algoritmo di Federated Averaging (FedAvg), decidendo di comparare le perfomance.
In inglese fanno un apple-to-apple comparison.
Anche senza la caffeina, è difficile annoiarsi.
Tornando a noi!
Per ciascun ciclo di allenamento con l’algoritmo di FedAvg, effettuano la loss evaluation sul validation set e immediatamente notano un problema:
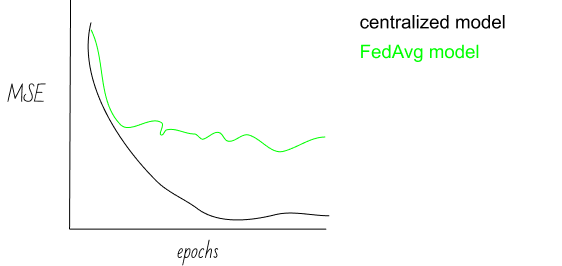
Addio convergenza.
Esattamente, il problema è dovuto alla natura dei dati di tipo non-IID.
Sampling Bias!
Esaminiamo con più attenzione i dati raccolti dal gruppo di amici.
Non avendo imposto regole restrittive al processo di raccolta, ognuno ha scattato un diverso numero di foto a ciascuno dei 10 animali, in virtù delle loro preferenze personali: sampling bias!
Possiamo osservare due pattern:
- Alcuni animali hanno più immagini degli altri nei singoli dataset (distribution skew)
- Alcuni amici hanno scattato più foto degli altri (quantity skew)
Distribution Skew
Esaminando la percentuale d’immagini ritraenti i singoli animali per ogni amico, notiamo una situazione ben lungi dalla perfezione:
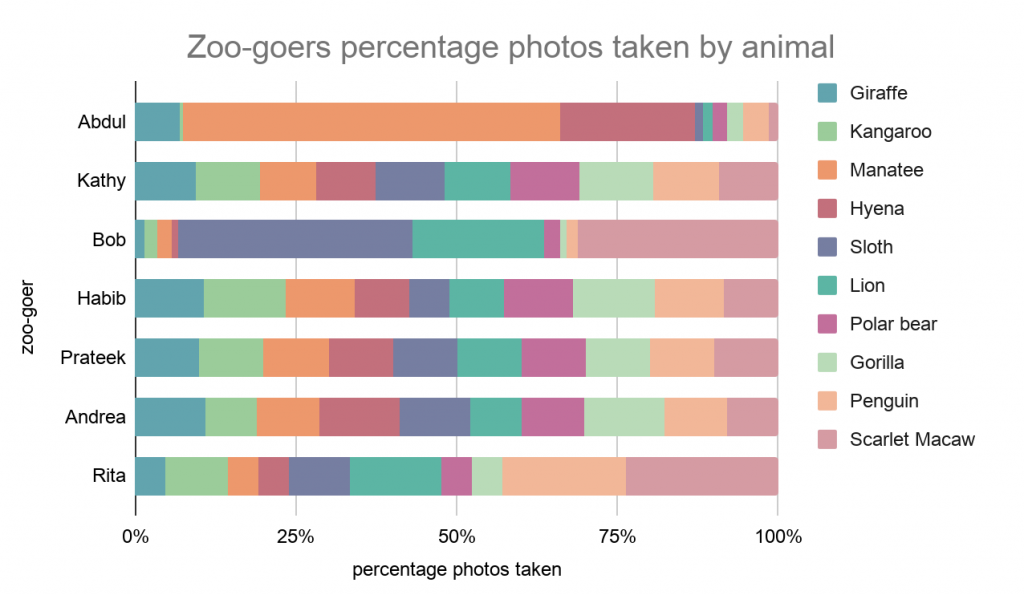
Le variazioni all’interno dei singoli dataset sono significative.
Abdul ad esempio è ossessionato dai piccoli lamantini.
Quantity Skew
La visualizzazione del numero assoluto d’immagini evidenzia poi il problema di quantity skew: la quantità d’imamgini raccolta da ogni amico varia notevolmente.
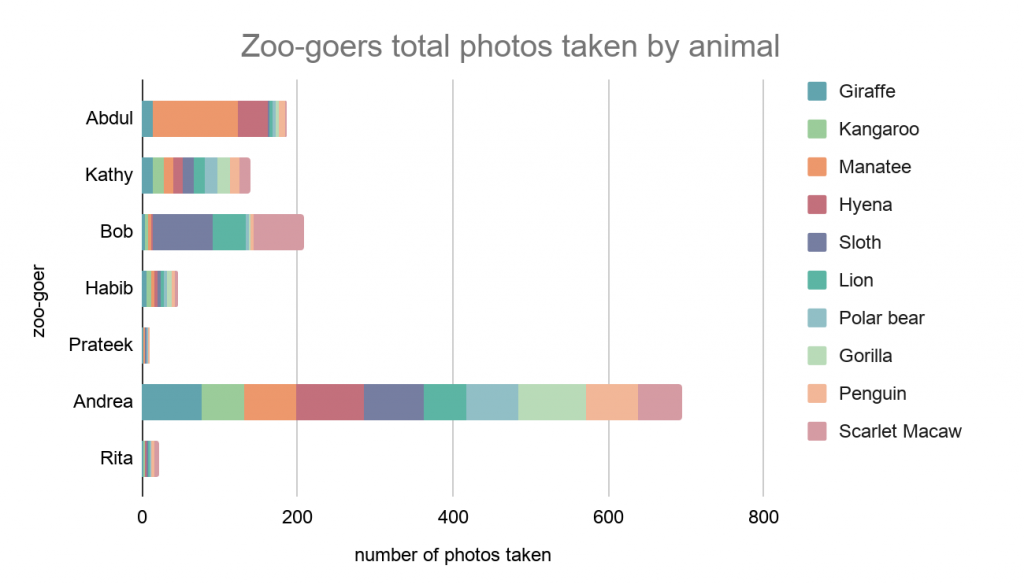
FedAvg vs non-IID
Possiamo quindi concludere che i dati non sono identicamente distribuiti (identically distributed).
Questo ostacola l’operato del FedAvg.
Il motivo è presto detto.
Per capire meglio quanto segue, ti consiglio di ripassare la spiegazione del funzionamento del Federated Averaging.
Consideriamo il momento del training sul dataset di Prateek: non ha scattato molte foto, pertanto il modello va costantemente in overfitting.
Prendiamo ora in considerazione il training sul dataset di Abdul. A causa dell’elevato numero di lamantini, per alcuni bacthes di allenamento il modello potrebbe ottimizzare unicamente la previsione della label “manatee“.
Il modello di Prateek e quello di Abdul finiscono per divergere su differenti local minima; quando il server coordinatore media gli updates al termine del training round, il risultato è privo di senso.
Questo scenario illustra pertanto come la presenza di non-IID impatti negativamente sulle prestazioni del FedAvg.
Non-IID Taxonomy
Concludiamo questo post proponendo una tassonomia, presentata da Hsieh et Al., per classificare le differenti tipologie di non-IID che possiamo incontrare in scenari reali.
Violazione d’identicità
I dati deviano dalla condizione di essere identicamente distribuiti. Circostanze comuni per cui questo avviene sono:
- Quantity skew: partizioni diverse contengono un numero di dati altamente differente (i.e. Alcune partizioni collezionano dati da meno device,o da quelli che producono meno dati)
- Label distribution skew: le partizioni sono legate a particolari regioni geografiche che fanno variare notevolmente le distribuzioni delle labels. (i.e. La faccia di una persona è presente solo in uno stato, così come i canguri sono limitati all’Australia e agli zoo.
- Same label, different feature: la stessa label può avere due diverse “feature vectors” in altrettanti dataset. L’esempio più significativo è l’immagine di un’auto coperta di sabbia ad Abu Dhabi, e di neve ad Oslo.
- Same feature, different label: gli stessi “feature vectors” possono essere associati a label differenti, a causa di preferenze personali. Label che riflettono il sentimento o la previsione della parola successiva hanno un forte bias personale o regionale (i.e. Culturale)
Violazione d’indipendenza
I dati deviano dall’essere indipendentemente tratti da una stessa distribuzione. Casi comuni di occorrenza di questo fenomeno:
- Intra-partition correlation: come due frame consecutivi in un video
- Inter-partition correlation: i dispositivi condividono una feature comune, come la temperatura.
Per il momento è tutto.
Un caldo abbraccio, Andrea.



