
Ieri era una calda domenica primaverile
Ieri c’erano 25 gradi e il caldo stava sciogliendo i coni gelato dei molti che avevano trovato refrigerio all’ombra di un albero… senza foglie… perché devono, giustamente, ancora crescere… tenuto presente che il 25 marzo generalmente le temperature non dovebbero superare i 15 gradi…
Chiusa la parentesi climate change, torniamo seri.
Mi sono appena accorto che la punteggiatura nel blocco precedente fa altamente schifo… ma tenuto presente che:
- è un blog
- le persone che leggono queste parole sono due, e uno è al piano -5 di Langley
- il post è un iLOG che segue l’andazzo dei miei pensieri
Ringrazia che il periodo ha senso logico, e trascura il resto.

Detto ciò, andiamo avanti.
Ieri google, che fornisce suggerimenti puntuali basandosi sulle ricerce degli utenti, ha giustamente consigliato un post su Medium.
Tradotto… mamma google mi ha sentito pronunciare le parole “annoiando” e “machine learning” e puff! Nuova email con gli articoli che cercavo. Spionaggio? No! Tecnologia! 🙂
Oggi mi sento in vena di frecciate che Robin Hood scansati proprio.

Dicevo…
Ho trovato questo articolo di un nostro connazionale, un cervello in fuga di nome Roberto, che ha giustamente deciso di lacsiare il bel paese per approfondire le nozioni di Data Analysis laddove le università non prediligono unicamente lo studio teorico: benvenuti a Varsavia.
Ho quindi deciso di condividere con te non solo la sua ricerca, peraltro egregiamente presentata nei suoi pdf che ti invito a consultare sul suo profilo github, ma anche alcune mie considerazioni che, ovviamente, non potevano mancare.
Premessa.
In questo post ho volutamente evitato di includere un’introduzione al natural language processing, che approfondirò invece in un’altra occasione. Detto ciò…
Partiamo.
NLP in python: un sunto con le informazioni essenziali
Roberto è stato formidabile nel presentare l’argomento con semplicità, senza però venir meno ai contenuti.
Prendendo spunto dalla sua creazione, che invito a leggere, ti propongo dunque un riepilogo che evidenzia, a mio avviso, quelli che ho trovato essere i punti fondamentali del processo di genesi del modello, così da risultare utili in ottica futura.
Inziamo.
Step 1 | Formalizzare il problema
Un po’ di contesto.
Partendo da un dataset contenente recensioni di diverse attività lavorative, vogliamo estrarre dal testo grezzo, vale a dire le recensioni pure e non ancora modificate, delle informazioni utili per creare un modello che consenta di determinare il punteggio assegnato dall’utente sulla base dei ‘toni’ e delle parole scelte nella recensione testuale.
Step 2 | Esplorazione preliminare sul dataset
Formalizzato il problema, dobbiamo fare nostro il dataset.
Cosa significa? Sapere vita, morte e miracoli dei dati su cui lavoreremo. Quanto più dimestichezza avremo con loro, tanto più bravi saremo nel realizzare un modello efficiente.
Il dataset in questione contiene 9 colonne (8 features e 1 label). Di queste, solo una è realmente utile: la recensione testuale. Diciamo dunque di vole prendere la variabile di testo come predictor e il punteggio in stelle (0 ~ 5) come target.
Step 3 | EDA: c’è bias?
Abbiamo già incontrato il processo noto come Exploratory Data Analysis, questa volta lo vediamo applicato ad un dataset meno corposo.
Come sappiamo, una buona analisi non può dirsi completa senza la determinazione del pattern di distribuzione, o più semplicemente la distribuzione della variabile: RStudio gioca a nostro favore.
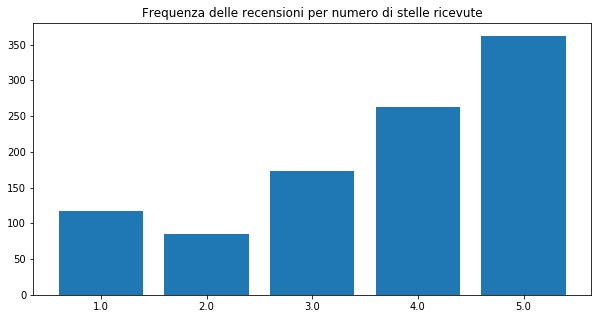
Come si evince dal grafico, il numero di valutazioni ‘positive’ è superiore a quello di valutazioni ‘negative’, assumendo 3.0 come punteggio scissorio.
E’ molto importante notare questa particolarità perché evidenzia una potenziale minaccia.
Il Bias.
Breve digressione: Bias
Pochi giorni fa ho pubblicato un post inerente al bias in una rete neurale artificiale, e ho visto insieme a te in che modo quello che abbiamo definito essere un parametro variabile possa incidere nella creazione di un modello, variando la soglia di attivazione di un neurone.
Ora però il termine bias assume un significato differente: è la distorsione del modello, la sua deviazione.
Deviazione rispetto a cosa? Entra in gioco l’etica!
Un modello deve essere oggettivo.
Per essere tale deve potersi addestrare in un campo neutro.
Condivido con te una metafora. Non è molto precisa, ma dovrebbe riuscire nel suo intento.
Considera il modello come un guerriero da allenare, e il dataset di training come la cultura dell’allenatore.
Caso A: Immaginiamo che l’allenatore abbia alti valori guerrieri, e veda il combattimento corpo a corpo come strumento di attacco: l’allievo crescerà con una mentalità forte, ma propense allo scontro.
Caso B: Immaginiamo che l’allenatore abbia alti valori guerrieri, e veda il combattimento corpo a corpo come strumento di difesa: l’allievo crescerà con una mentalità forte, ma propense all’intesa.
Spero che questa breve metafora riesca a trasmettere il punto chiave del discorso: l’allievo ideale sarà colui che, allenato da entrambi i guerrieri, prenderà la corretta decisione dinanzi ogni situazione.
Step 4 | Gestire il Bias
Tornando a noi, abbiamo notato la presenza di bias. Vediamo come gestirlo.
Roberto ha deciso di suddividere il dataset in sotto-insiemi, di valutazioni positive e negative, per usare questa distinzione come variabile dipendente.
Step 5 | Preprocessing
E’ mandatorio pre-processare i dati.

- rimuovere caratteri non utili nelle valutazioni (slashes, punteggiatura, tag HTML)
- convertire l’intero testo in minuscolo.

Per farlo possono essere usate funzioni ad-hoc che implementano librerie specifiche. Utili a questo proposito sono i moduli:
- ReGex (regular expression operations)
- collections (counter e deque)
Step 6 | Visualising Data
A questo punto, può tornare utile avere dare uno sguardo alla rappresentazione visiva dei dati. Per farlo, dal momento che stiamo analizzando testi formati da parole, è conveniente usare una nuvola di parole (word cloud)
Step 7 | Before Modeling
La regressione lineare è un buon metodo per risolvere il nostro problema.
Prima di procedere con l’implementazione occorre apportare gli ultimi cambiamenti al dataset, affinché possa effetivamente essere usato nelle operazioni di training.
In applicazioni come questa, il testo contiene elementi superflui come:
- parole di stop (stopwords come articoli e preposizioni, in generale parole di singificato nullo). L’operazione di eliminazione è detta removal of stopwords
- verbi coniugati (l’interesse è il signficato, quindi il verbo nella sua forma base); L’operazione di trasformazione è detta stemming
Risolvere questi problemi non basta. Un computer elabora dati, non parole.
Occorre quindi dare al dataset una rappresentazione numerica, operando la vettorizzazione dei dati. In inglese, vectorization.
Per questo scopo è stata creata una classe apposita della libreria sklearn:
sklearn.feature_extraction.textCountVectorizer
Step 8 | Migliorare il modello
Il primo modello creato necessita spesso di miglioramenti che ne facciano aumentare l’accuratezza.
La regola aurea è aumentare il numero di osservazioni, quindi la granddezza del dataset. Quando questo non è possibile, modificare l’algoritmo di allenamento può rivelarsi utile.
In questo ambito, un algoritmo può essere perfetto in un caso e pessimo in un altro. Provare è quindi fondamentale per individuare il migliore, che possa assicurare l’indice di affidabilità maggiore.
Tenendo a mente che abbiamo operato due operazioni di modifica singnificative, quali stemming e stopwords elimination, il cambiamento dei parametri che le controllano incide sull’affidabilità del modello.
Spero che queste informazioni, possano tornarti utile. Ti auguro una buona giornata!
Un caldo abbraccio, Andrea.



