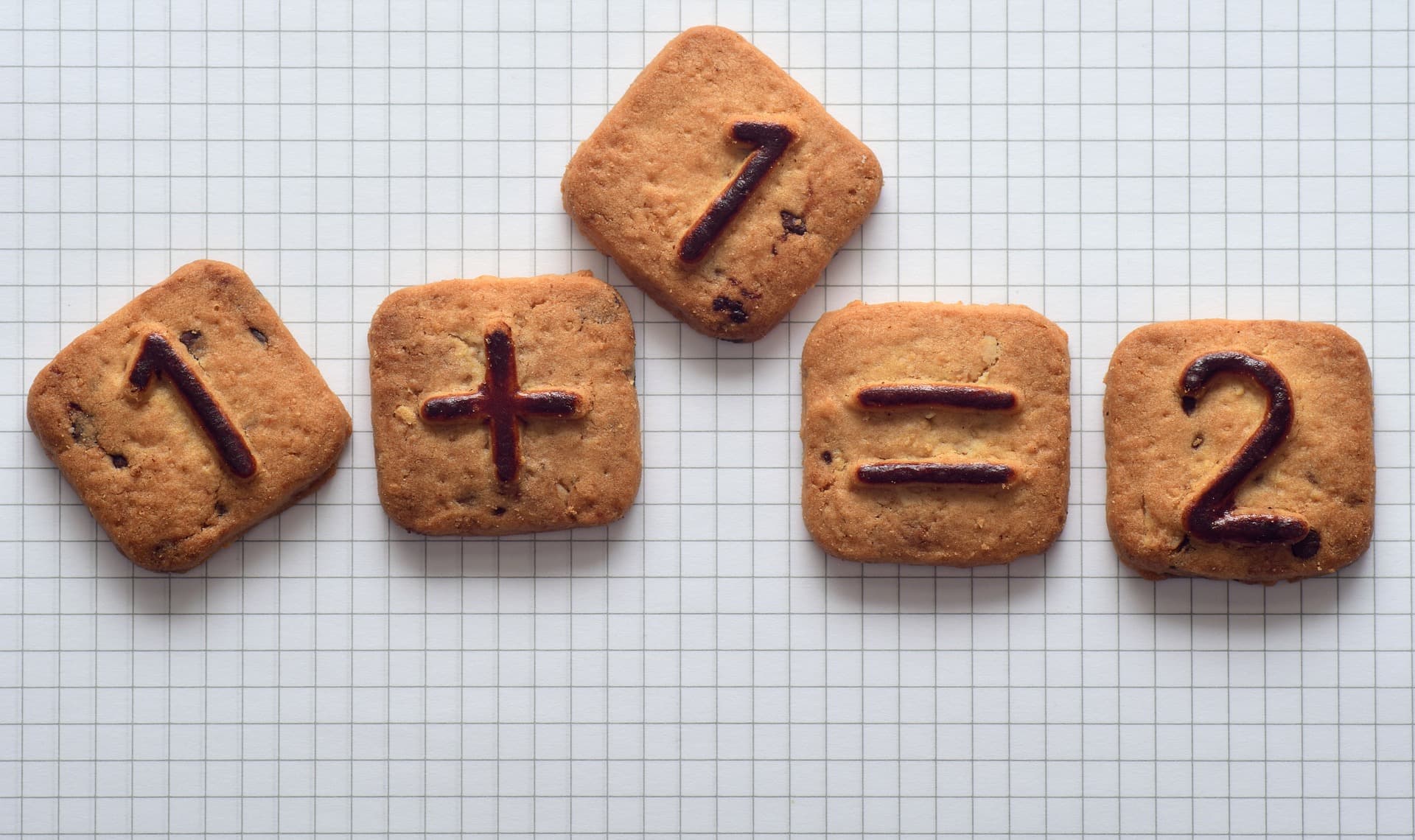
Per valutare efficacemente le prestazioni di un modello di machine learning, l’unico sistema è usare dati nuovi. Atraverso il model testing e model evaluation si determina quanto il modello abbia generalizzato bene.
Model Testing
Esistono due principali approcci per il problema:
- train and test on the same dataset
- train / test split.
Train and Test: same dataset
Il nome di questa procedura è sufficientemente esplicativo.
Consideriamo un problema di regressione, il cui intento è calcolare il valore continuo di una variabile dipendente a partire da più exaplanatory variables, le variabili indipendenti.
Il nostro dataset, per questioni di semplicità, è piccolo: appena 10 osservazioni.
Usiamo l’intero dataset per la fase di training.
Quindi decidiamo che una porzione del dataset, composta da 4 osservazioni, sia usata per valutare le performance del modello.
Ora, il valore della label delle 4 osservazioni definito actual value è confrontato con quello predetto per ciascuna di esse, chiamato invece predicted value.
In questo modo determiniamo l’erore del modello.
Un simile approccio è descritto dalle seguenti particolarità:
- High training accuracy
- Low out-of-sample accuracy
In effetti il modello ha imparato a conoscere i dati di testing nella fase di training.
Prima di capire perché questa cosa non ci piaccia per niente, concentriamoci un attimo sui due nuovi termini.
Training Accuracy
Training Accuracy è la percentuale di previsioni corrette effettuate dal modello valutato sul dataset di testing.
Un valore eccessivamente alto di questa metrica è un segnale d’allarme, poiché il modello potrebbe essere in overfitting.
Ecco perché da solo non basta.
Out-of-sample Accuracy
Out-of-sample Accuracy è la percentuale di previsioni corrette effettuate dal modello su dati mai visti prima, assenti dunque nel dataset di training.
Conclusione: model testing con le pinze
Per concludere, usare gli stessi dati per model training e model testing è una soluzione utile quando il dataset è particolarmente piccolo. Occorre però considerare i problemi che ne derivano.
Potrebbe sembrare scontato, ma il nostro obiettivo è massimizzare l’out-of-sample accuracy.
Come possiamo raggiungerlo?
In altri termini, in che modo possiamo aumentare la nostra out-of-sample accuracy?
Train / Test Split
Quindi il nostro obiettivo è fornire al sistema di machine learning nuovi dati da elaborare, che non abbia usato nella fase di training.
Il problema è: i dati sono preziosi e limitati.
In pratica dobbiamo accontentarci dell’unico dataset in nostro possesso.
Quello che facciamo allora è dividere il nostro unico dataset in due insiemi che chiamiamo:
- training set, sarà usato nella fase di training per consentire al modello di apprendere la reazione nascosta tra i dati;
- testing set, sarà usato nella fase di testing per valutare le prestazioni di generalizzazione del modello, calcolando l’errore tra i risultati predetti e quelli reali;
Normalmente 80% del dataset è l’insieme di training, la parte restante è chiamata hold out e, per completezza d’informazione, costituisce il 15%.

Niente paura hold out è il 20% del dataset originario! Avevi calcolato bene!
L’errore previsionale calcolato sul testing set è definito generalization error (o out-of-sample error). Questo errore stabilisce quanto bene il modello performi su istanze mai viste prima.
Qalora il generalization error fosse basso nel dataset di training e alto in quello di testing, il modello sarebbe in overfitting.
Quindi per valutare un modello, occorre semplicemente usare un testing set!

Non corriamo troppo.
Train/Test split è un metodo efficace, che dividendo il dataset in gruppi mutually exclusive (che si escludono a vicenda) fornisce una visione più chiara delle reali prestazioni del modello.
Ha però un difetto: dipende fortemente dalla composizione del dataset.
Approfondiamo questo concetto.
Model Evaluation
Facciamo una supposizione.
Abbiamo due modelli, uno lineare e uno polinomiale (li approfondiremo successivamente) e intendiamo stabilire quale sia il migliore.
Confrontiamo il generalization error, e decretiamo che il modello lineare performi meglio.
Ora, intendiamo regolarizzare il modello per evitare l’overfitting modificando il valore di un suo hyperparameter. Quale valore?
Per capirlo alleniamo 100 modelli usando altrettanti valori, e verifichiamo quale sia il migliore.
Supponiamo quindi di aver trovato un particolare valore tale che produca un generalization error, (out-of-sample error) del 5%.
Questa metrica indica quanto bene il nostro modello generalizi su istanze mai viste prima.
Ottimo. Lo rilasciamo in produzione e… la monitorazione ci informa che l’errore è del 15%.
Com’è possibile?
Presto detto.
Abbiamo misurato l’errore di generalizzazione più volte sullo stesso testing set. In questo modo è come se avessimo allenato il sistema a sviluppare il modello migliore per quel particolare set di dati.
Soluzione? Il validation set
Validation Set
Il validation set è un secondo hold out set, sottoinsieme del training set, cioè di quel 80% del dataset originario.
Quindi il flusso è il seguente.
- Alleniamo diversi modelli con multipli hyperparameters usando il training set.
- valutiamo i modelli attraverso il validation set producendo un validation score.
- scegliamo il modello con il più alto validation score
- calcoliamo il generalization error usando il testing set.
K-Fold Cross-Validation for model testing
Ormai hai imparato la regola aurea secondo cui i dati sono tutto.
better data defeats fancier algorithns
Non possiamo permetterci di sprecare dati per fare dei test sempliciotti. Quindi, una tecnica utile a tal fine è la cross-validation.
Il cross-validation è un sistema che prevede la divisione del training set in sotto insiemi complementari. Ogni modello è allenato su una combinazione differente dei sottoinsiemi e validato usando la parte restante.
Giusto per chiarezza.
La cross-validation è una tecnica, che viene usata con la divisione del dataset in training set e testing set. Il training set è ulteriormente diviso in sottoinsiemi, alcuni dei quali costiuiscono il validation set. Comunque presente.
K-fold, fa riferimento al numero variabile d’insiemi (fold) identificati dal parametro k. Quindi potremmo avere 6-fold, 10-fold, 20-fold cross validation, a seconda delle dimensioni del dataset.
Trovato il modello migliore, una nuova fase di training è eseguita sull’intero dataset con quella combinazione specifica d’iperparametri.
Un caldo abbraccio, Andrea.



