
MAX Image Segmenter è un sistema che sfrutta un modello open source di deep learning capace d’individuare differenti tipologie di oggetti, segmentare le loro forme e permetterci d’interagire con loro.

Oh yes, i log sono tornati.
La nostra avventura!
MAX Image Segmenter: Description
IBM ha una ricca collezione di modelli open source chiamata Model Asset eXchange (MAX). Uno di questi è in grado di automatizzare il processo di estrazione di oggetti da singole immagini, permettendoci di ridurre drasticamente il tempo necessario per l’editing foto: è il MAX Inage Segmenter
Andremo ad avviare un’applicazione web (Web App) capace d’identificare oggetti pixel-by-pixel.
Ogni unico oggetto sarà poi evidenziato da un colore univoco, e andremo quindi a realizzarne una mappa-colori.
Realizzando quella che viene in gergo detta segmentazione semantica, e per cui abbiamo tanto dannato in passato, saremo in grado di considerare ogni oggetto come immagine indipendente potendola inserire in ogni altra foto.
Fantastico gente. Come diamine avviamo il tutto?
Il nostro punto di partenza, come spesso accade per i log, è una fantastica repository di GitHub.
Guida vs Log
Qualora fossi nuovo, o nuova, benvenuto e benvenuta!
Quello che stai leggendo è un log e non una guida. Qual è la differenza?
Lascia che ti spieghi una piccolissima cosa, cruciale, perché ci tengo molto a te, e non vorrei vederti triste o in preda alla frustrazione.
Nel tentativo di riprodurre i miei passi, potresti non riuscire a completare il progetto, rendendolo cioè funzionante.
Questo perché a differenza di una guida, in cui ci prendiamo il tempo per capire bene cosa deve essere fatto e in che modo, un log è la becera trascrizione di azioni che compio, e potrebbe mancare di step fondamentali che ho eseguito sul mio computer in precedenza.
Ho ideato i log per fati capire quanta fatica possa celarsi dietro un semplice progetto!
Rappresentano il dietro le quinte di uno spettacolo teatrale: la guida vera e propria, a breve pubblicata… forse 🙂
Non è detto che l’impresa riesca.
Sarà memorabile.
Basta indugiare, iniziamo
MAX Image Segmenter: docker, react, tensorflow, Node e python??
Bestiale ragazzi.
Ho un’euforia che fatica a contenersi. Sono le tecnologie più all’avanguardia sul mercato, usate da grandi aziende e che attualmente muovono buona parte delle applicazioni web su scala globale.
Tutte qui, riunite in un’unica web app.

Dato che siamo a 400 parole e ancora dobbiamo iniziare, comincio a tagliare corto.
Per prima cosa procediamo con l’attivazione di docker.
Ottimo era già avviato.

Cloniamo la GitHub repository:
https://github.com/IBM/MAX-Image-Segmenter-Web-App.git
E ci spostiamo al suo interno.
Iniziano le danze!
Avviamo la prima immagine di docker:
docker run -it -p 5000:5000 -e CORS_ENABLE=true codait/max-image-segmenter
In questo modo avviamo il MAX microservice
La documentazione ci avvisa che la creazione dell’immagine genera automaticamente una Swagger API documentation interattiva
Ok, l’indirizzo è inquietante: http://0.0.0.0:5000/
In realtà indica che qualsiasi indirizzo è valido purché sia sulla porta 5000.
E via così niente documentazione non si riesce a caricare…
Seguiamo la guida aprendo un’altra shell e lanciando un npm install
Adesso dovremmo avviare l’applicazione.
Si salvi chi può!
Ma vacca viola.
Scusa Seth!
Manca il db… pouchdb
No manca tutto diamine!
Vuoi avere tutte le versioni aggiornate? Sto gayser, serve python compreso tra 2.7 e 3.0 e invece noi abbiamo la 3.7… Ecco perché manco la documentazione interattiva riusciamo a far partire (anche se potrebbe non dipendere da questo)
Scarichiamo l’ultima versione aggiornata di python 2.7
E la installiamo.
Giusto perché ci rimangono 60 GB di spazio sul SSD. Ho più memoria libera sullo smartphone… assurdo.
Ora chissà dove cavolo finirà l’installazione… a breve lo scopriamo.
Prepariamoci a lanciare nuovamente npm i. Stiamo compilando una marea di file…
Niente da fare, ancora una miriade di errori. Aggiorniamo pouch db e poi avviamo tramite docker
Ed effettivamente mancava puchdb

Il mio dubbio però è che il server comunque non risponda…
Proviamo.
Ah Ah.
Abbiamo una connection refused su http://localhost:5000/model/predict
Fantastico il nostro amato server è down.
Dobbiamo risolvere.
Back al back-end
Ci rimane il 30% di batteria e windows ci avvisa che lo finiremo in 30 minuti.
Ma ottimo.
Stiamo buildando una nuova docker image
Capsita siamo dei geni abbiamo avviato due volte la stessa app, una però dentro docker…
Altro giro altra corsa, proviamo con docker compose: avvieremo fron-end e back end in un unica app e poi cercheremo di capire cosa non funziona.
I log sono così: a testa dura per farlo partire!
Ho dvouto lanciare un netcfg -d a causa di un possibile vSwitch attivo e riavviare il computer.
Vediamo.
Docker sta partendo.
Ahimé nulla da fare per oggi!
Aggiornamento del 19/10/2019:
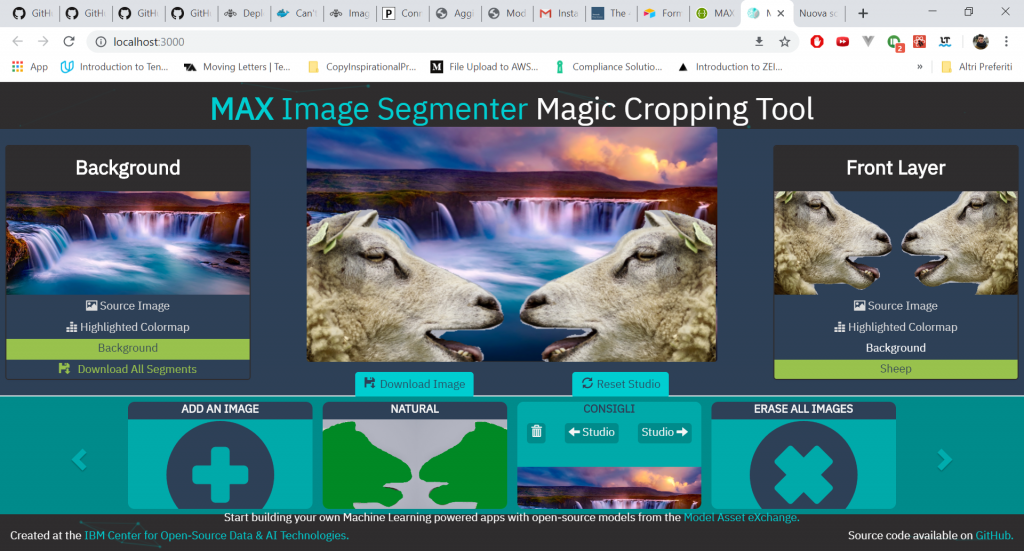

Ovviamente ci siamo riusciti!
Ora qualche picco exploit che abbiamo dovuto seguire.
Per prima cosa docker ha un funzionamento particolare che andrebbe approfondito, specie a livello di networking.
L’unica cosa importante è sapere che l’indirizzo 0.0.0.0 non funziona a dovere, o probabilmente andrebbe gestito in altro modo. Quindi come ci siamo collegati?
Questa mattina, aprendo il computer, l’istanza di docker era stata sospesa per inattività e era saltato fuori un port mapping particolare:
192.168.99.1:52362->192.168.99.100:2376
Effettuando qualche ulteriore ricerca, mi sono imbattuto in alcuni post riguardanti il nostro problema ed è saltato fuori che Docker Toolbox avvia le istanze sulll’indirizzo 192.168.99.100
Quindi è bastato connettersi alla porta 500 et voila: la pagina con le API di swagger!
Nei prossimi giorni arriveranno nuovi aggiornamenti!
Stay tuned!
Un caldo abbraccio, Andrea.



