
Google Explainable AI (xAI) è il nuovo servizio di BigG. Uno strumento per risolvere il problema delle Black Box nei progetti di Data Science che richiedono lo sviluppo di modelli di Machine Learning.
Ok gente.
Qui abbiamo parecchi termini da spiegare.
Procediamo con ordine.
The Blackbox problem
Un modello di machine learning genera una funzione che mappando features e label è capace di effettuare previsioni puntuali con un certo grado di accuratezza.
È una definizione riduttiva ma funzionale.
Ora c’è solo un problema.
Immaginiamo di aver gestito un classification problem e che il nostro classificatore binario sia in grado di determinare se un particolare utente della banca X possa o meno ripagare un debito.
Inseriamo i dati di un nuovo utente nel sistema e il risultato è chiaro. Non pagherà il debito.

Perché?
A: “Come perché… lo dice il modello…”
B: “E su quale base…?”
A: “Beh i dati”
Perfetto! Una cosa del genere non può funzionare, ma è proprio questo il punto.
Possiamo conoscere il dataset a memoria, e il funzionamento matematico dell’algoritmo come le nostre tasche.
Non è difficile visualizzare i coefficienti della funzione di training, ma capirne il peso che ciascuno di essi esercita sulla previsione richiede strumenti più sofisticati.
Il nostro modello è in questo momento una Black Box: entrano gli input, sono elaborati in qualche magico unicornoso* modo, ed escono gli output.
*(candidato Treccani 2020)
Questo è valido a maggior ragione per le reti neurali artificiali, specie quelle profonde (Deep Neural Network).
In queste situazioni, il loro sistemi interni sono schermati da decide di livelli computazionali che rendono assai difficile il riconoscimento di bias e errori.
Vediamo un caso pratico.
X-Ray Bias
Attraverso una model evaluation standard non è sempre facile individuare eventuali problemi con i dati, persino seguendo le best practice di divisione del dataset in train/validation/test sets o k-fold cross valdiation, un tema caro a cui dovremmo dedicare un approfondimento, è possibile incorrere in gravi problematiche.
Facciamo un esempio.
Un image pathology model è allenato per identificare diverse patologie da immagini a raggi X.
Le performance del modello sono ottime sul test/holdout set (approfondiremo anche questo, tranquillo).
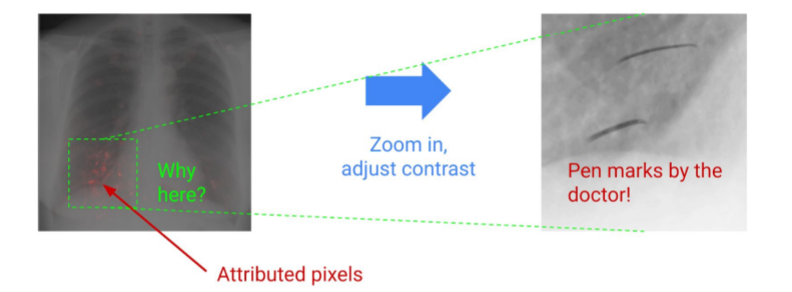
Il modello ha imparato a riconoscere dei segni lasciati dai dottori sulle lastre come elementi caratterizzanti, come feature.
Il problema è quando questa feature assume un valore importante e determina l’esito della previsione.
Ovviamente non serve spiegare perché un simile comportamento è indesiderabile: le performance in produzione verrebbero influenzate negativamente.
Data science Bias
In un progetto più classico, un modello di machine learning su un dataset potrebbe attribuire un peso eccessivo a un campo accidentalmente lasciato dal data scientist, come un ID.
Tutto questo senza un chiaro segno di errore.
Google Explainable AI Service
Come possiamo risolvere queste problematiche?
Google Explainable è nato proprio per questo.
L’obiettivo è quello di fornire ai al team AI aziendale uno strumento in grado di produrre insights sul funzionamento nascosto dei sistemi implementati.
Non sui dati, sugli strumenti.
Questo sistema è rivolto a:
- Model developers & data scientist
- Product Manager
- Business Leaders
Il valore aggiunto che Google Explainable AI è in grado di conferire a un progetto di machine learning è incredibile.
Gli sviluppatori sono ora in grado di spiegare agli stakeholders il comportamento di un modello e non solo le fasi che ne hanno portato alla creazione o il risultato prodotto.
Shapley Values
Il funzionamento di Google Explainable AI si basa sui così detti Shapley Values.
Spesso le feature in un dataset hanno un certo grado di dipendenza. Per questa ragione attribuire loro l’impatto generato sulla previsione finale è complicato.
Google Explainable AI sfrutta il concetto di Shapley del cooperative game tehory, proposto nel 1953.
Lo approfondiremo nei prossimi giorni. Per il momento puoi consultare il AI Explainability Whitepaper, per qualche dettaglio aggiuntivo sul nuovo prodotto di google.
Qui invece puoi accedere al servizio vero e proprio.
Un caldo abbraccio, Andrea



