
Il funzionamento di una rete generativa avversaria (GAN) è complesso: cercheremo di semplificarlo e approfondirlo con i giusti esempi e le dovute spiegazioni.
Nel precedente post abbiamo visto cosa sono le GAN: Generative Adversarial Networks.
Una piccola tappa fondamentale nel nostro viaggio.
Ottimo!
Lasciami fare una breve digressione.
Devi sapere che mi piace molto il mare, e l’idea di navigare come veri esploratori in acque incontaminate.
Questo è il motivo per cui ricorro spesso alla metafora del marinaio e del comandante.
Continua a leggere…
Oltre a farci vivere l’avventura e il piacere della scoperta, è quasi allegoria di una vita equilibrata in cui a volte ci troviamo nei panni di un capitano che deve decidere, guidare e tenere la rotta, e altre siamo l’umile marinaio che ascolta, ed esegue a tesa china con sommo rigore le disposizioni del capitano.
Allora lasciami dire una cosa.
Il porto è ormai lontano e il mare aperto potrebbe sembrare intimidatorio.
Non temere, perché il nostro capitano ci guiderà in queste insidiose acque, lontano dai pericoli, verso l’attesa destinazione.
Quindi? Con il vento di levante, issiamo le vele: alla scoperta del funzionamento delle GAN!
Come funziona una rete generativa avversaria (GAN)
Citando l’articolo accademico di Yoshua Bengio, un informatico canadese che ha studiato l’apprendimento profondo, il Deep Learning promette di scoprire ricchi, modelli gerarchici che rappresentano distribuzioni di probabilità su dati quali immagini, conversazioni audio, e testo.
Al di là dei livelli di complessità di una simile definizione, quello che dobbiamo sapere sono, per il momento, le basi.
L’obiettivo ultimo di un progetto di Deep Learning è sviluppare un modello che rappresenti una certa realtà: un’immagine, un testo, etc.
Quindi partiamo dai dati, di cui disponiamo, stabiliamo delle funzioni matematiche e attraverso iterazioni successive e l’ausilio di qualche gran bel algoritmo, ricaviamo i parametri che definiscono la funzione, di conseguenza il modello.
A questo punto è molto utile approfondire il funzionamento delle Reti Neurali Convoluzionali, di cui abbiamo parlato qui.
Mi raccomando, tornerà utile tra poco.
Tornano a noi, sembra semplice il funzionamento?
Quando si tratta d’imparare, o apprendere, da dati presenti… Abbastanza. Perlomeno è intuitivo.
Come facciamo però a generare dei dati che siano verosimili?
Ecco che entrano in gioco le GAN.
Nel precedente post abbiamo chiarito che il framework di Generative Adversarial Nets prevede due Deep Networks: un generatore, Generator G, e un discriminatore, Discriminator D.
Prima di capire come allenare un generatore, comprendiamo il sistema attraverso cui avviene la generazione dell’informazione: una immagine.
Generating random variables
Come input per il nostro modello, occorre generare dei numeri casuali.
Questa apparentemente semplice operazione nasconde un’insidia.
I computer, queste stupide seppur preziose macchine, sono sistemi deterministici per natura.
Cosa significa?
È teoricamente impossibile generare numeri realmente casuali (potremmo aprire una digressione filosofia sul concetto di casualità, anche se per il momento penso sia meglio tralasciare).
La soluzione è definire algoritmi che generino sequenze numeriche, le cui proprietà risultino affini a quelle generate casualmente.
Aumentando la complessità, possiamo dire che usando un generatore numerico pseudocasuale siamo in grado di creare sequenze di numeri che seguono approssimativamente una distribuzione uniforme tra 0 e 1.
Si tratta di un caso elementare questo: variabili casuali complesse possono essere inizializzate con sistemi differenti.
Un esempio?
Metodi di Inverse Tranform Samping, molto utili per stupire colleghi e amici, ma poco per comprendere davvero il funzionamento di un Rete Generativa Avversaria.
Non facciamoci distrarre dalle affascinanti sirene lungo il tragitto: manteniamo il focus sull’orizzonte.
Ora che abbiamo il nostro input z, usiamo il Generator G per creare un’immagine x.
Perfetto. Finito. Tutti amici come prima.
Beh… non proprio.
Concettualmente, z è la rappresentazione delle caratteristiche latenti dell’immagine generate.
Quali sono queste caratteristiche? Non chiedere. Non le conosciamo.
Vedi, questa è la magia: non controlliamo il significato semantico di quelle caratteristiche, lo gestisce interamente la rete neurale e spetta al processo di training capire quali siano.
Facciamo finta che tu sia una persona ostinata e curiosa.
Vuoi sapere cosa accada under the hood ? Benissimo!
Possiamo stampare le immagini generate ed esaminarle.
Come ci spiega questo articolo accademico, ecco l’aspetto dei volti che potremmo ottenere:

Ok Ok.
Non so te, ma a me sembra ci siano parecchi buchi di logici.
Come funziona il generatore?
Il Generator di una rete generativa avversaria
Come per le Reti Neurali Convoluzionali, anche le GANs hanno un ventaglio di architetture tipicamente usate. Una di queste è la DCGAN, una delle più popolari per la rete generativa.
Attraverso convoluzioni multiple trasposte eseguiamo l’upsampling da z per generare x. Per semplificare concettualmente l’argomento, possiamo considerare la struttura un deep learning classifier con un funzionamento opposto:
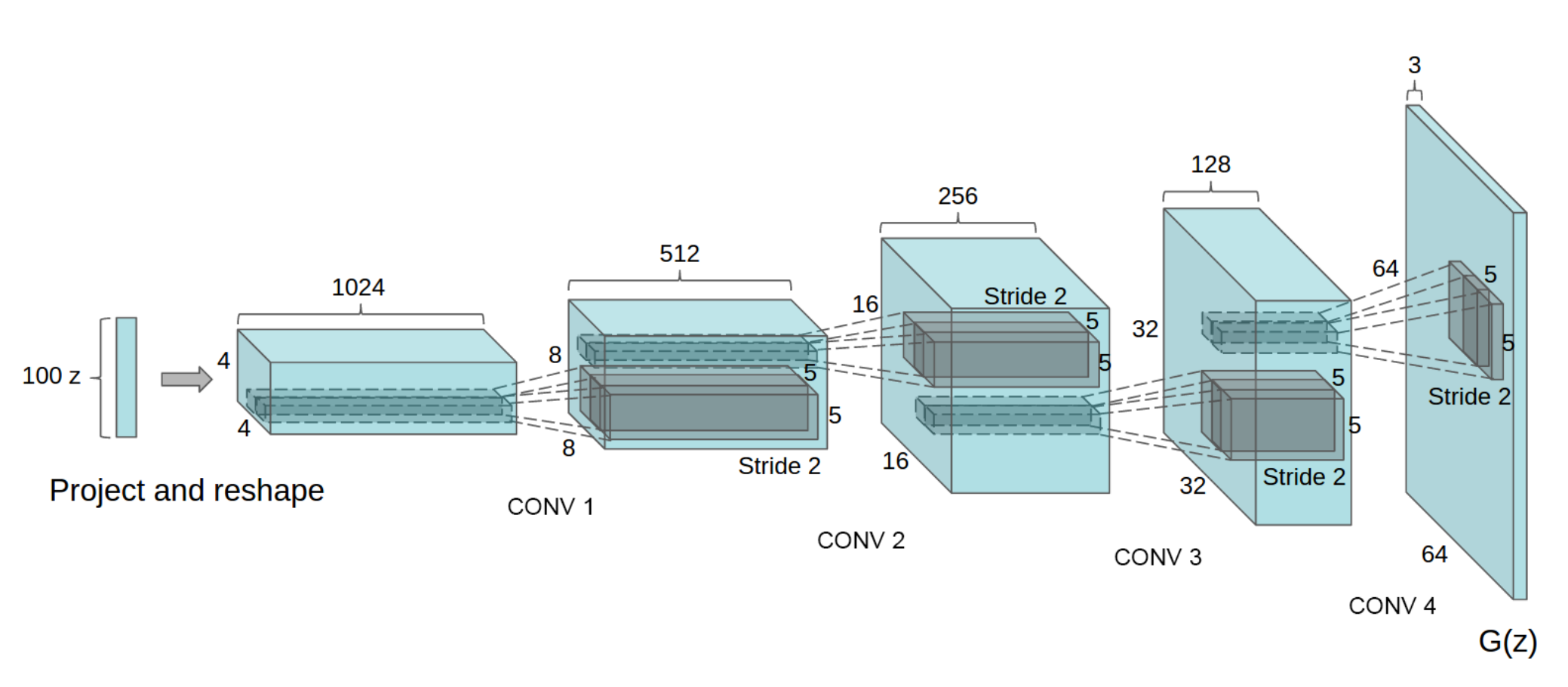
Il funzionamento dei layer convoluzionali lo abbiamo spiegato qui.
Ora arriva il bello.
Devi sapere che un Generator sarebbe in grado di produrre puro rumore.
E vorrei ben vedere! Gli diamo in pasto numeri casuali, e lui dovrebbe tirare fuori un dipinto impressionista in pieno stile Monet?
Palesemente qualcosa non torna.
Un momento. Dove hai messo il Discriminator?
Ecco prendilo.
Il Discriminator di una rete generativa avversaria
Il Discrimintaor guida il Generator sull’immagine da creare.
Consideriamo un’applicazione di GANs, nel dettaglio una così detta CycleGAN. I dettagli li vedremo in un prossimo post.
Per il momento devi sapere che questa rete può applicare a un’immagine reale lo stile di Monet.

Allenato con immagini reali e generate, una Generative Adversial Nets è in grado di affinare il Discriminator per riconoscere le caratteristiche veritiere.
Lo stesso Discriminator fornisce poi un feedback al Generator affinché crei dipinti simili a quelli di Monet.

Ok. Ok.
Tecnicamente però, cosa diamine succede?
Il Discriminator esamina le foto reali (del dataset di training) e genera immagini separatamente.
Produce una probabilità D(x) che l’immagine in input sia reale o fittizia

Il Discriminator è simile a un deep network binary classifier: 1, immagine reale; 0, immagine generata.
Allo stesso tempo vogliamo però che il Generator crei immagini che riproducano quelle reali, e che siano quindi interpretate dal Discriminator come D(x) = 1.
Ancora una volta, l’algoritmo di retropropagazione dell’errore corre in nostro soccorso.
Lo abbiamo studiato nel post sul funzionamento delle reti neurali, che ti invito a leggere.

Al termine del processo di training, i modelli di GAN convergono e producono immagini che sembrano reali.
Ora è arrivato il momento di sporcarsi le mani e iniziare a scrivere qualche riga di codice.
Ti consiglio allora questo corso: non te pentirai!
Per il momento è tutto.
Per aspera, ad astra.
Un caldo abbraccio, Andrea



