
Folium è una python data visualization library creata con l’intento di aiutarci nella visualizzazione di geospatial data, i dati geospaziali.
Nei precedenti post abbiamo analizzato dei metodi di data visualziation base, semplici e avanzati.
Capita sovente che all’interno del dataset siano presenti coordinate geografiche. Come possiamo rappresentarne il valore al meglio?
Scopriamolo!
Folium
La libreria Folium consente la facile creazione di una mappa per qualsiasi luogo nel mondo, a patto che si disponga delle relative coordinate.
La visualizzazione predefinita fa uso di OpenStreet Map.
Possiamo creare:
- Mappe
- Marcatori sovrapposti
- Cluster di mappe
Inoltre sono disponibili differenti stili, tra cui:
- Street Levl Map
- Stamen Toner Map, utile per evidenziare corsi d’acqua e aree costiere
- Stamen Terrain Map, utile per visualizzare aree montuose e vegetazione.
Rispetto ad altre librerie multiuso, Folium gestistisce unicamente questa particolare tipologia di dati, e offre illimitate chiamate API in modo totalmente gratuito.
La documentazione è reperibile qui.
Geospatial Data Python Tutorial
Per questo breve tutorial useremo il California Housing Dataset, che raccoglie dati catastali californiani datati 1990. Vecchiotto, ma funzionale.
Il dataset è reperibile all’interno della repository ageron, sviluppata per la parte pratica del libro Hands-On Machine Learning, di cui consiglio l’acquisto: una risorsa formidabile!
ATTENZIONE
Per limitare la prolissità del post, ho riportato il solo codice relativo all’analisi dati geospaziali. Onde evitare lacune e incomprensioni, ti consiglio di fare sempre riferimento al Jupyter Netbook allegato a fondo pagina, dove puoi trovare tutto il flow completo del tutorial.
Importiamo il dataset, quindi creiamo una mappa della California centrata nell coordinate medie, ottenute con describe(), nel dataset.
# defined the world map centerd around california with a higher zoom level world_map = folium.Map(location=[35,-119], zoom_start=6) #[lat, long] # display the world map world_map
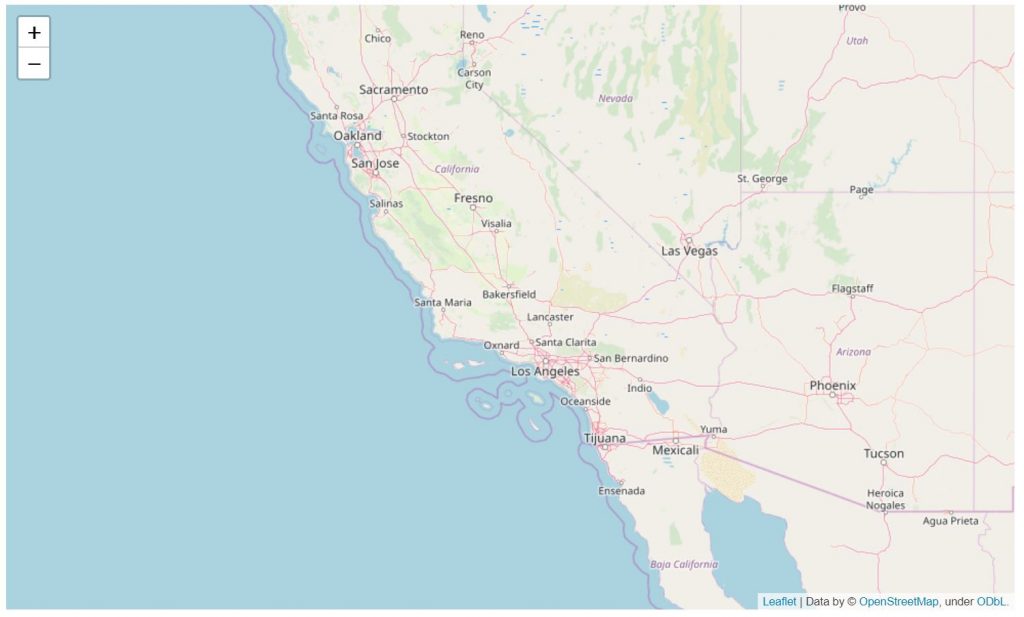
Attraverso il parametro tiles siamo in grado di controllare lo stile della mappa. Possiamo scegliere tra:
- Stamen (Terrain, Toner, Watercoolor)
- Mapbox Bright
- CartDB
- Mapbox Control Room
# defined the world map centerd around california with a higher zoom level world_map = folium.Map(location=[35,-119], zoom_start=6, tiles="Mapbox Bright") #[lat, long] # display the world map world_map
Quest’ultima tipologia di mappa è simile a quella default: nasconde però i bordi degli stati a zoom bassi, e ne riporta i nomi in lingua inglese (contrariamente a visualizzarli nella relativa lingua)
Markers
Aggiungiamo alla mappa dei datapoints:
# define our map's parameter and superimpose single datapoint
lat = 37
lng = -122
# create the map
california_map = folium.Map(location=[lat,lng], zoom_start=12)
# in order to superimpose the locations of the datapoint we firstly create a feature group with its own feature and style,
# then add it ot the map
# instantiate a feature group for the datapoints in the dataframe
datapoints = folium.map.FeatureGroup()
# add each datapoint ot the feature group
for lng, lat in zip(df.longitude, df.latitude):
datapoints.add_child(
folium.vector_layers.CircleMarker(
[lat, lng],
radius=5, # set the markers width
color='green',
fill=True,
fill_color='white',
fill_opacity=.2
)
)
# add pop-up text to each marker
lats = list(df.latitude)
lngs = list(df.longitude)
labels = list(df.housing_median_age)
for lat, lng, label in zip(lats, lngs, labels):
folium.Marker([lat, lng], popup=label).add_to(california_map)
# add datapoints to map
california_map.add_child(datapoints)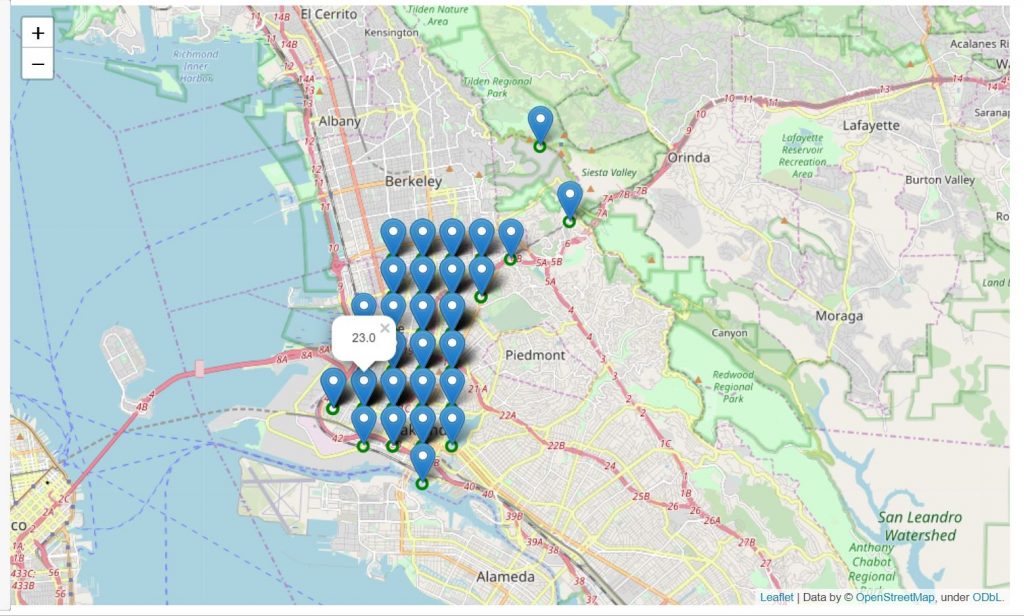
Map Clusters
Prima di salutarci un rapido sguardo alla creazione di map cluster, particolarmente utile per evitare un’eccessiva congestione di dati.
from folium import plugins
# let's start again with a clean copy of the map of California
california_map = folium.Map(location = [lat, lng], zoom_start = 12)
# instantiate a mark cluster object for the datapoints in the dataframe
datapoints = plugins.MarkerCluster().add_to(california_map)
# loop through the dataframe and add each data point to the mark cluster
for lat, lng, label, in zip(df.latitude, df.longitude, df.housing_median_age):
folium.Marker(
location=[lat, lng],
icon=None,
popup=label,
).add_to(datapoints)
# display map
california_map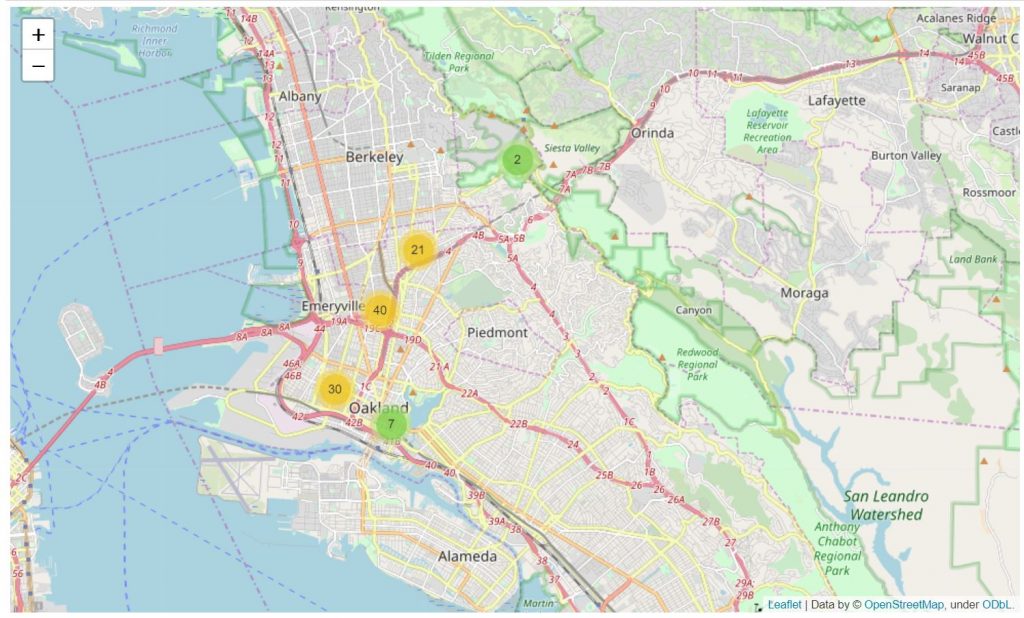
Folium Choropleth Maps
Choropleth Map (Mappa Coropletica) è una mappa tematica con aree colorate di differente tonalità in proporzione alla magnitudine della variabile statistica rappresentata su di essa.
Una Choropleth Map rappresenta un sofisticato sistema per la visualizzazione delle misurazioni variabili in funzione dell’area geografica.
Un esempio, la distribuzione di popolazione per miglio quadrato in USA.
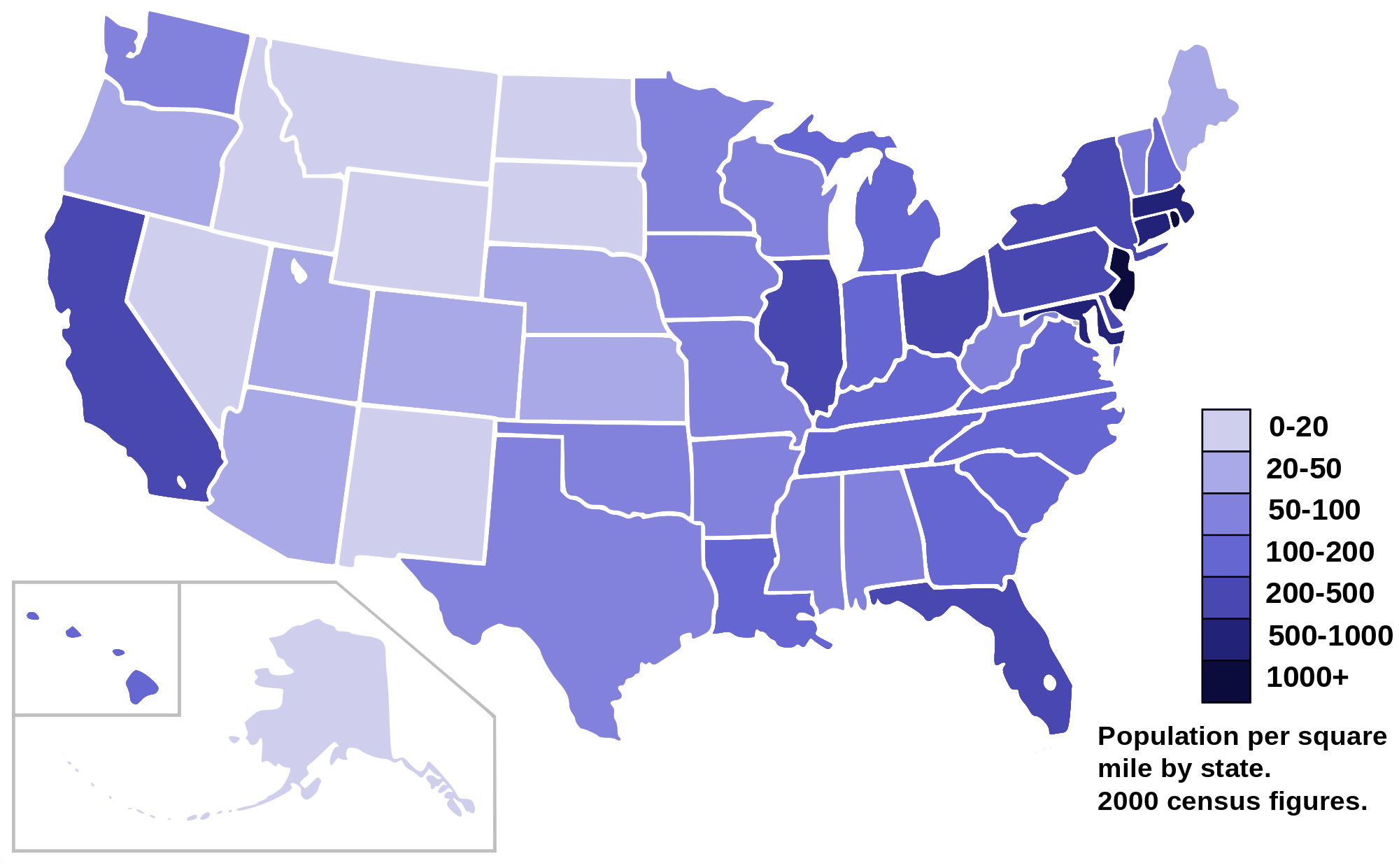
La realizzazione di una mappa simile è complessa. Folium agevola il lavoro, benché sia necessario che si disponga di una particolare struttura dati riportante i contorni di demarcazione delle diverse aree tematiche.
Una volta in possesso del file, generalmente un json, puoi procedere come segue:
json_boundaries = r'boundaries.json' # geojson file
# create a plain world map
World_map = folium.Map(location=[0, 0], zoom_start=2, tiles='Mapbox Bright')
# overlap the geojson
World_map.choropleth(
geo_data=json_boundaries,
data=df,
columns=['Columna A','Columna B'],
fill_color='YlOrRd',
key_on='some.key.CASE.SENSITIVE',
fill_opacity=0.7,
line_opacity=0.2,
legend_name='A legend name'
)
# display map
World_map
Occhio ad alcuni elementi:
- il key_on è la key all’interno del file json contenente la variabile d’interesse. Per determinarla è necessario aprire il json ed esplorarlo. Ricorda che le key del JSON sono case sensitive, occhio a maiuscole e minuscole.
Un caldo abbraccio, Andrea.



