
Il CRISP-DM, acronimo di Cross-industry standard process for data mining è un processo standardizzato che descrive e codifica gli approcci comuni impiegati dagli esperti di data mining: è il modello analitico più usato nell’industria.
Sappiamo che i dati sono gli elementi base in ogni processo di data science e machine learning che si rispetti.
Ancora prima di averli tra le mani e saperli analizzare, è importante raccoglierli, e bene.
Infatti la qualità dei dati influenza ogni lavoro svolto su di essi.
Per dirla in altro modo: “garbage in, garbage out“.
L’attività di data mining serve dunque a raccogliere efficacemente i dati e le informazioni così da svolgere su di essi importanti ricerche e trarre fondamentali conclusioni.
Scopriamo insieme le basi del CRISP-DM.
CRISP-DM: Cross-industry standard process for data mining
Il CRISP-DM divide l’operazione di data mining in 6 parti essenziali:
- Business Understanding
- Data Understanding
- Data Preparation
- Modeling
- Evaluation
- Deployment
A differenza di altri processi convenzionali tipicamente lineari e unidirezionali, le fasi che caratterizzano il CRISP-DM sono pensate per essere reiterate ciclicamente.
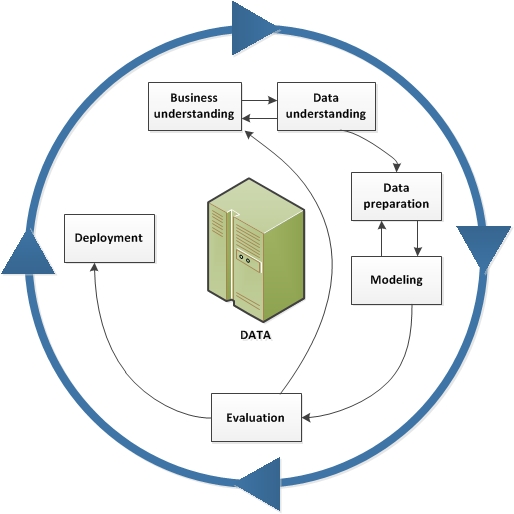
Nell’immagine puoi chiaramente notare le dipendenze più importanti e frequenti tra le diverse fasi, e come l’ordine non sia rigoroso: in base alle necessita di un progetto è possibile spostarsi avanti e indietro molteplici volte.
Un esempio che fornisce la stessa IBM, azienda che nel 2015 propose la metodologia ASUM-DM (qui maggiori info) come estensione del CRISP, è quello di una compagnia interessata a identificare il riciclaggio di denaro.
In questo caso la flessibilità del CRISP è adattata alle esigenze: è probabile che siano passate in rassegna enormi quantità di dati senza uno specifico obiettivo di modellazione.
Il lavoro si concentra dunque sulla fase di Data Understanding (Data Visualization e Data Exploration, o Exploratory Data Analysis) anziché quella di Modeling.
Abbiamo quindi visto come a seconda dei contesti, le differenti fasi sino posizionate in scale d’importanza variabile.
È comunque fondamentale tenere traccia delle eventuali domande e riflessioni emerse in ognuna di esse perché molto rilevanti per una pianificazione a lungi termine.
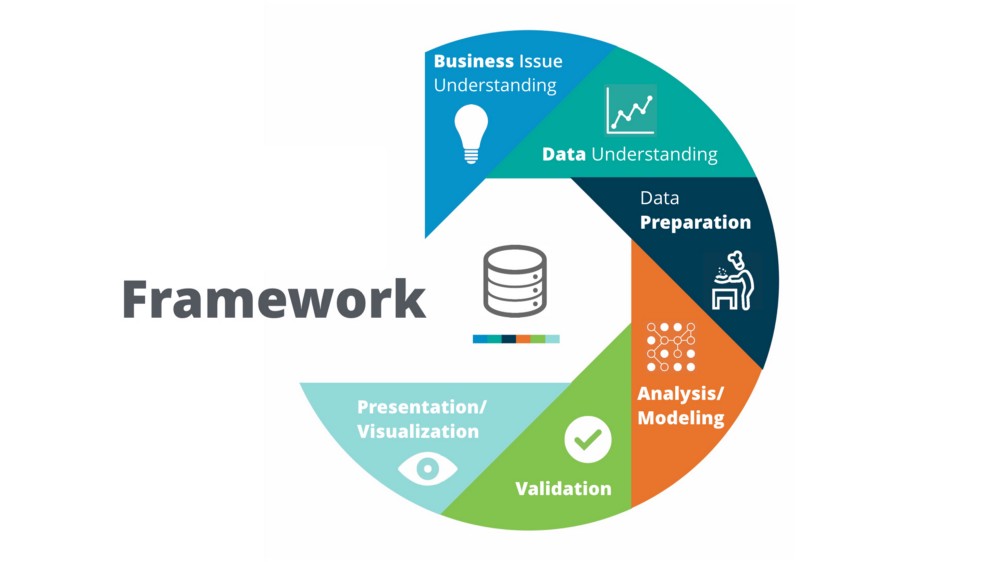
Questa metodologia si collega perfettamente alla data science methodology che abbiamo accuratamente analizzato nel nostro percorso, iniziato proprio con la fase di Business Understanding.
Puoi approfondire qui!
Per approfondire invece l’argomento centrale del post, puoi consultare la pagina di IBM a questo link.
Per il momento è tutto.
Un caldo abbraccio, Andrea.



