
Google Colab è una piattaforma online gratuita che offre un servizio di cloud hosting di Jupyter Notebooks, con il supporto a GPU.
Possiamo usare differenti librerie come PyTorch, Tensorflow, Keras e OpenCV giusto per citarne alcune.
Google Colab ha dei limiti, come evidenziato dalla pagina FAQ, ma la versatilità che il servizio offre è in grado di offuscarli facilmente: quando li raggiungeremo, cercheremo altre soluzioni.
Per muovere i primi passi con Tensorflow, è il posto giusto.
Puoi creare il tuo primo neurone artificiale per la risoluzione di un problema reale direttamente attraverso Tensorflow 2.
In effetti avremmo tranquillamente potuto eseguire tutto il codice di questo post direttamente in locale, sul nostro personale Jupyter Notebook di fiducia, ma in questo modo i nostri orizzonti sarebbero stati limitati.
Accendiamo i motori, ie prepariamoci per il divertimento!
Configurazione Google Colab
Puoi raggiungere il servizio cliccando su questo semplice link.
Prima d’iniziare a programmare, ti consiglio caldamente alcune impostazioni da configurare per massimizzare la tua produttività.
Abilitazione GPU
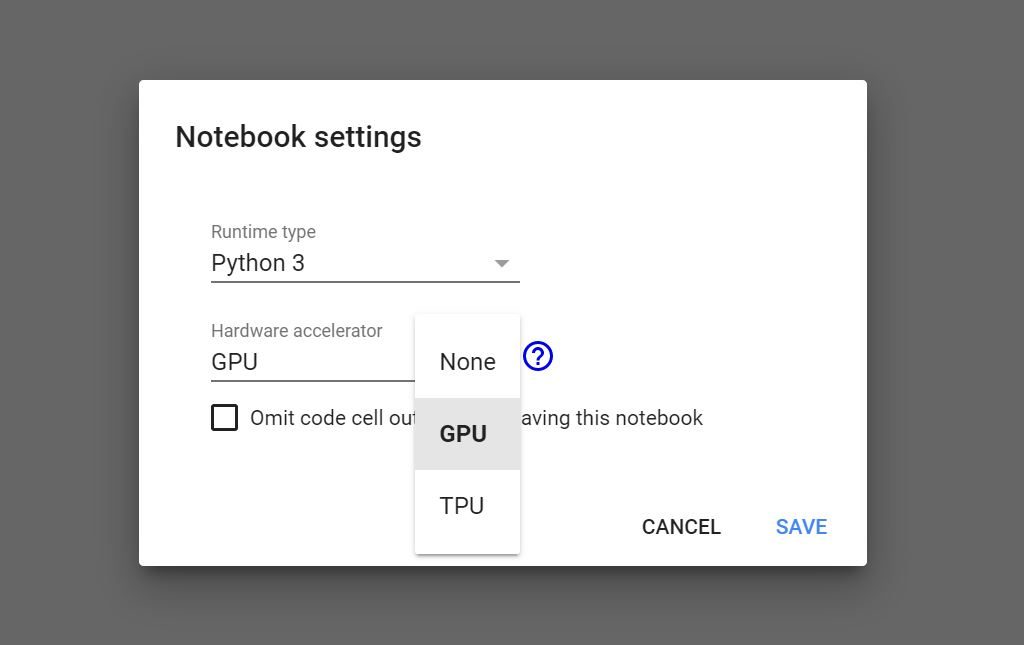
Abilitiamo la GPU recandoci su runtime in alto a sinistra, e cliccando su change runtime type nel dropdown che compare. Quindi alla voce hardware accelerator selezioniamo GPU. Esploreremo le Tensorflow Power Unit (TPU) in un altro momento.

In breve, sono unità computazionali appositamente studiate per gestire carichi di lavoro in ambito machine learning e data science, come hai certamente intuito.
Mount Google Drive
Google Drive e Colab sono entità separate, ma potrebbe tornare utile associarle, sia per questioni di comodità che di ordine.
Tutti i nostri notebook potranno all’occorrenza essere salvati sul nostro personale spazio di archiviazione. Per attivare Google Drive, ci basta digitare:
from google.colab import drive
drive.mount('/content/gdrive')Ho cambiato il blocco del codice. Questo stile è material… ma potrei modificarlo…
Esegui il codice in una cella: sarà generato un url sul quale dovrai cliccare. A questo punto, effettuando l’accesso con il tuo account Google verrà creato un codice alfanumerico che dovrai copiare e inserire nell’apposito campo all’interno del Notebook.
Con l’authorization code confermato abbiamo ora la cartella di drive connessa!
Import / Load CSV File from Google Drive
Qualora avessimo la necessità d’importare un classico file CSV, o in generale un qualsiasi dataset esterno, questa funzione potrebbe rivelarsi particolarmente utile.
from google.colab import files uploaded = files.upload()
Dando invio, comparirà un input field da cui potremo comodamente caricare il nostro file, procedendo quindi alla sua successiva importazione attraverso il modo standard:
# import dataset
df = pd.read_csv("./dataset.csv")
# display first 5 elements
df.head() Ora possiamo finalmente cimentarci in qualche progetto di Kaggle o alle nostre analisi da veri data scientist.
Un caldo abbraccio, Andrea.



