
Le convolutional neural network (CNN), o rete neurali convoluzionali, nascono dagli studi condotti sulle cortecce prefrontali animali e sono impiegate nei processi di image recognition sin dal 1980.
L’obiettivo di questo post è chiaro: comprendere le convolutional neural network a livello funzionale e studiarne gli usi pratici e le possibili applicazioni future.
Convolutional Neural Network
L’idea dietro una rete neurale convoluzionale è applicare un filtro alle immagini prima che queste vengano processate dalla rete neurale profonda (Deep Neural Network): una rete neurale artificiale
Convolutions
Un convolution è un filtro che passa su un’immagine, la elabora ed estrae feature dalle caratteristiche comuni.
L’applicazione del filtro consente quindi di mettere in rilievo i dettagli delle immagini cosicché sia possibile trovarne il significato e identificare gli oggetti.
A livello pratico, un filtro altro non è che un insieme di moltiplicatori (a set of mutlipliers).
Esaminiamo un esempio.

Consideriamo un’immagine in bianco e nero di 28×28 pixel (una di quelle presenti nel MNIST) e prendiamo il pixel con valore 192.
Decidiamo quindi di applicare un filtro definito in precedenza (al come ci arriviamo) al contenuto di un’immagine.
Matematicamente non facciamo altro che moltiplicare il valore del pixel con quello del filtro: il 192 viene quindi moltiplicato per 4.5.
Anche ciascuno dei riquadri vicini è moltiplicato per i rispettivi valori del filtro.
Evidentemente, in questo modo otteniamo una nuova immagine.
Ecco un’illustrazione visiva del funzionamento:
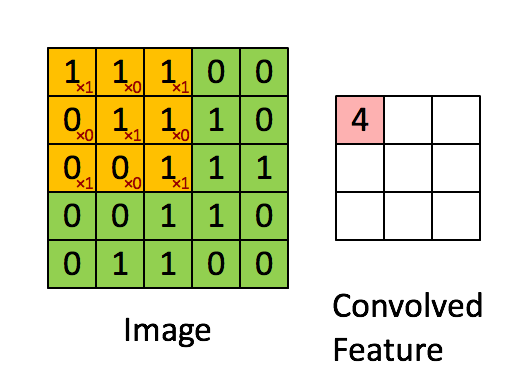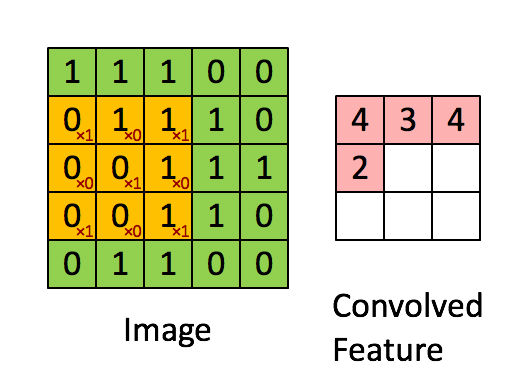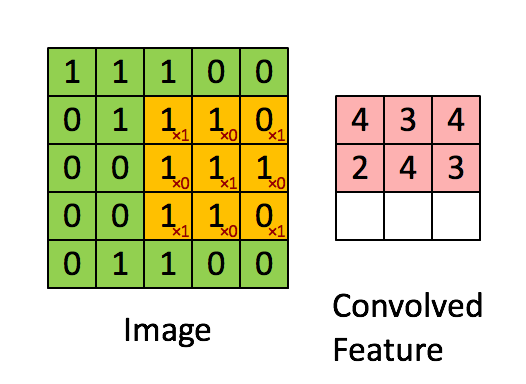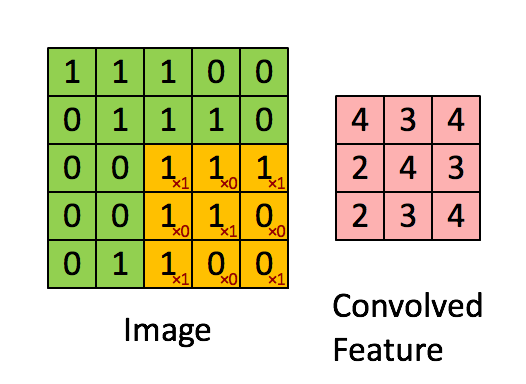
Ci piace! Perché?
Osserviamo come differenti filtri siano in grado di evidenziare specifici pattern nell’immagine.


Pooling
Una seconda classe di filtri è definita di pooling: i pixel sono ora raggruppati e filtrati in un sottoinsieme.
Esistono differenti varianti di pooling, una tra queste è quella di max pooling: l’immagine originale è raggruppata in set di 2×2 pixel, quindi viene considerato solo quello di valore più alto.
L’applicazione di questo filtro consente la riduzione delle dimensioni a un quarto delle originali, pur mantenendo le caratteristiche iniziali.
La domanda che sorge spontanea è: come scegliamo l’aspetto e il valore del filtro?
Ecco la magia delle reti neurali convoluzionali: i filtri sono parametri i cui valori vengono appresi nel processo di apprendimento automatico, nella fase di training.
Quando la nostra immagine entra nel livello convoluzionale (convolutional layer) un numero definito a priori di filtri inizializzati casualmente (randomly initializied) viene applicato producendo un risultato passato al secondo livello della rete.
Il processo si ripete finché la rete non individua quei valori dei filtri tali per cui il matching tra l’immagine in input e il valore predetto produca meno errori possibile: il processo è noto come feature extraction.
Con questo ultimo concetto siamo arrivati alla fine della nostra breve introduzione!
Cosa ci riserva il futuro? Scopriamolo assieme!
Un caldo abbraccio, Andrea.



