
Un efficace sistema per valutare propriamente le performance di un sistema di machine learning è guardarne la confusion matrix.
In questo post capiamo cos’è e come funziona.
Confusion Matrix
Tra poco le cose inizieranno a diventare nebulose, sarà allora che apprenderai il motivo per cui la chiamano: matrice di confusione.
Prima però, facciamo un passo indietro ed esaminiamo un case study.
Una nota azienda, attiva nel settore energetico, ci ha contattato perché allertata dal crescente tasso di licenziamenti volontari registrati.
Evito di tediarti a lungo e giungo al punto: il problema è diminuire le dimissioni, prevedendo una possibile richiesta di allontanamento sulla base di alcune metriche raccolte dall’azienda e riferite ai singoli dipendenti.
Compiuta la fase di business understanding e definito l’analytic approach migliore, abbiamo raccolto i dati di cui avevamo bisogno e capito quali di questi fossero in nostro possesso.
Quindi abbiamo eseguito l’exploratory data analysis e finalmente siamo giunti allo sviluppo del modello.
Supervised classification model
Ora però dobbiamo valutarne le prestazioni. Ma che modello è?
E’ un modello di classificazione binaria, più tecnicamente un supervised classification model.
Trattasi di classificazione perché la variabile target, la nostra label, è discreta, e la definiamo binaria poiché assume uno dei due valori possibili:
- left (abbandona l’azienda)
- stay (resta nell’azienda)
Poiché gli algoritmi di machine learning gestiscono numeri, e non stringhe, dobbiamo mappare la binary label in formato numerico comprensibile.
Nei problemi di classificazione binaria, come questo, distinguiamo dunque tra i valori predetti:
- una classe positiva (generalmente quella di nostro maggiore interesse)
- una classe negativa (ovviamente, il valore restante)
Nel nostro caso left è la positve class e stay è la negative class.
e tra i valori reali:
- True (generalmente quella di nostro maggiore interesse)
- False (ovviamente, il valore restante)
Model Output
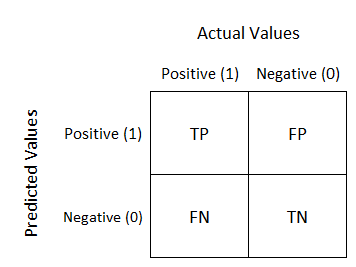
Un classificatore binario produce 4 possibili risultati:
- un vero positivo
- un falso positivo (type 1 Error)
- un vero negativo
- un falso negativo (type 2 Error)
Nel nostro modello usiamo un metodo di cross validation: una parte del dataset di training (con label nota) è usata come se fosse un dataset di testing.
Ti ricordo inoltre che la classse positiva è left.
Ora consideriamo che il dipendente con _id: A012-b1 ha lasciato l’azienda. Il suo status (noto) è left.
Il modello può prevedere che lo status dell’osservazione con _id: A012-b1 è:
- left (vero positivo)
- stay (falso negativo)
Ora consideriamo invece che lo status noto dell’osservazione con _id: A012-b2 è stay, metre il valore prodotto può essere:
- left (falso positivo)
- stay (vero negativo)
Ecco perché la definiamo confusionaria… ma aspetta, perché la parte intricata deve ancora venire.
Confusion Matrix in reality
Nella realtà una confusion matrix è meno esaltante di quanto tu possa credere:

Prima di procedere devi sapere che esistono differenti varianti di confusion matrix, a seconda di come si decida di costruirla.
In quest post ho scelto di descrivere la variante prodotta dalla funzione confusion_matrix() di Scikit-Learn.
In questa versione, ogni riga rappresenta una classe reale (actual class):
- la prima [944, 27] è quella negativa,
- la seconda [0, 29] è quella positiva
Potresti però trovare in rete altre fonti che definiscono la confusion marix inserendo sulle righe le classi predette (predicted class) anziché quelle reali (actual class) come nell’esempio qui riportato.
Ogni colonna costituisce poi una classe predetta (predicted class):
- la prima [944, 0] è quella negativa,
- la seconda [27, 29] è quella positiva
Come se non bastasse potresti trovare in rete altre fonti che definiscono la confusion marix invertendo l’ordine della natura delle classi, quindi potresti trovare una cosa simile a questa:
Tornando al nostro esempio, inoltre:
- 944 sono le classi true negative (predette negative ed effettivamente lo sono. Stay for Stay)
- 27 sono le classi false positive(predette positive invece che negative. Left for Stay)
- 0 sono le classi false negative(predette negative invece che positive. Stay for Left)
29 sono le classi true positive(predette positive ed effettivamente lo sono. Left for Left)
Un consiglio per imparare bene la logica della confusion matrix è ripetere ad alta voce ragionando sul valore delle parole e tenendo, perlomeno inizialmente, un foglio con su scritto quale sia la classe positiva e quale quella negativa
Un classificatore perfetto avrebbe solamente true negative e true positive, e la sua confusion matrix apparirebbe riempita sulla diagonale top left bottom right.
Abbiamo quindi visto che una confusion matrix fornisce molte informazioni. Spesso sono però utili metriche più concise: la precisione e il recupero (precision recall).
In questo post, trovi una visione d’insieme sulle tecniche di model evaluation
Un caldo abbraccio, Andrea.



