
In questo articolo scopriamo come funziona Deep Learning!
Prima però, i convenevoli sono d’obbligo.
Mi chiamo Andrea Provino e da circa un anno sviluppo articoli su Data Science, Machine Learning e molto altro, studiando insieme a te questi affascinanti mondi, un articolo alla volta.
Il mio obiettivo è chiaro: aiutarti a comprendere temi complessi spiegandoti semplicemente, con esempi divertenti e descrizioni complete, i complessi temi che caratterizzano l’intelligenza artificiale.
Oggi capiamo senza scendere nel tecnico, come funziona Deep Learning.Il
Deep Learning
Il Deep Learning, sotto insieme del Machine Learning, sfrutta reti neurali artificiali per processare dati non strutturati.
Per capire come funziona il Deep Learning occorre dunque capire come funzionino le neural networks.
Come funziona Deep Learning
Le reti neurali sono organizzate in livelli computazionali, o layers.
Ogni livello computazionale è composto da diversi nodi interconnessi, o neuroni, che svolgono delle operazioni sui dati in ingresso.
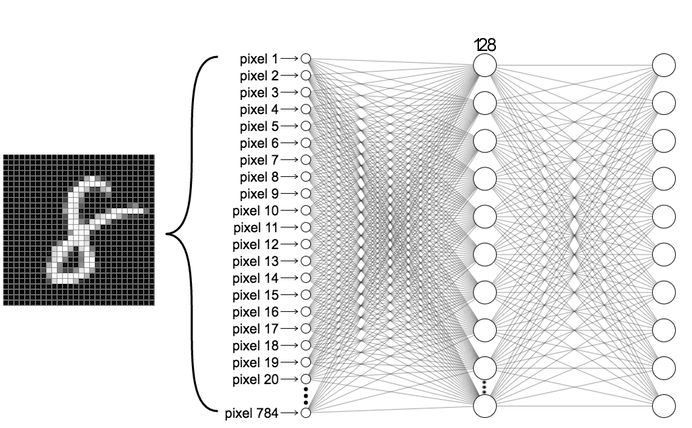
Ciascun neurone riceve quindi un numero di valori pari a quello dei nodi presenti nel precedente livello, e ne calcola la somma.
Ogni linea che crea quell’intricato garbuglio nell’immagine superiore.
Ciascun canale lega quindi un neurone a quello successivo.
Come funziona il Weight
I canali sono poi detti pesati o weighted channels perché la magnitudine di ogni valore trasmesso da un nodo all’altro è influenzata da un parametro chiamato weight.
Anche la somma calcolata dal neurone è definita pesata o weighetd sum.
A questo risultato sommiamo poi un ulteriore parametro chiamato bias.
Come funziona il Bias
Il bias associato a ciascun neurone e il weight di ciascun canale sono dinamici perché autoregolati dalla rete durante la fase di apprendimento.
Per questo parliamo di apprendimento automatico: il sistema, attraverso iterazioni successive e specifiche funzioni matematiche, determina in modo autonomo i valori ottimali dei parametri.
Quelli cioè che descrivono la migliore catena di operazioni da compiere per passare dal dato in ingresso, che può anche essere un’immagine, al dato in uscita, ad esempio il nome dell’oggetto identificato.
Alla weighted sum (somma pesata) di input, sommata al bias, si applica poi una funzione, definita di attivazione.
Come funziona l’Activation Function
L’activation function aggiunge non linearità alle trasformazioni eseguite e determina l’attivazione, o meno, del neurone e cioè il passaggio dell’informazione a quelli successivi.
Quindi seppur ogni neurone è collegato ai precedenti e successivi non è sempre detto che le informazioni calcolate siano trasmesse in avanti nella rete.
Queste trasformazioni non lineari ci servono perché in loro assenza ci limiteremmo ad applicare delle funzioni lineari, che difficilmente descrivono la complessità del nostro mondo.

Attraverso delle trasformazioni non lineari progressive, il livello di astrazione dei dati in ingresso aumenta sino all’ultimo layer, quello definito output layer che produce di norma una distribuzione di probabilità sulle classi possibili.
In definitiva il motivo per cui trovi ancora difficoltoso dare una rappresentazione mentale netta a questi due mondi, machine learning e deep learning, è perché il confine tra i due è solo sfumato.
Come funziona deep learning | Conclusione
Chiaramente questo articolo è solo un’introduzione a come funziona il deep learning e ci sono diversi elementi che dobbiamo prendere in considerazione, e che faremo prossimamente, per avere una comprensione ancora più profonda.
Capisco però il tuo interesse!
Ecco perché condivido con te alcune risorse che potresti trovare interessanti nel frattempo.
Su questo articolo abbiamo approfondito il funzionamento delle Reti Neurali Artificiali, chiarendo ulteriormente come funziona deep learning.
Per accedere a una fonte internazionale, ti rimanderei invece a qui.
Abbiamo invece approfondito il concetto di bias qui.
Per il momento è tutto.
Per aspera, ad astra.
Un caldo abbraccio, Andrea.



