
Un Bloom Filter è una struttura dati di tipo probabilistico impiegata per determinare l’appartenenza di un elemento a un insieme in modo efficiente.
Definizione fornita! Ora posso tornare a leggere documenti noiosi.
Per il momento è tutt..
Non così in fretta.
Concedimi la tua attenzione ancora per qualche minuto.
Cos’è un Bloom Filter? | Approfondimento
Quando parliamo di struttura dati di tipo probabilistico, ci riferiamo a un efficiente e curioso modo di salvare informazioni in memoria.
In pratica con un Bloom Filter possiamo avere la certezza che un dato elemento non sia presente nel filtro, ma solo una probabilità che invece lo sia.
In altri termini, è impossibile che un Bloom Filter fornisca un falso negativo ma è possibile che ci siano falsi positivi.
Intrigante, specie perché la seconda spiegazione è più complessa della prima.
Pensi che ti stia sfuggendo qualche particolare? Lasciami aggiungere che puoi inserire un nuovo elemento in un Bloom Filter, ma non puoi rimuovere quelli presenti e che all’aumentare della lunghezza del filtro (i.e. Degli elementi inseriti) cresce la probabilità di ottenere falsi positivi.
Ora hai il quadro completo.
Mi mancavano strumenti con una logica così contraddittoria, e apparentemente paradossale.
Sappi però che c’è una specifica ragione che ne motiva l’esistenza e l’utilizzo.
Qui ci serve una buona dose di concentrazione. Procediamo con ordine.
A cosa serve un Bloom Filter?
In questi anni ho letto decine di libri di crescita personale, dozzine di pubblicazioni accademiche e migliaia di parole su documenti online vari.
Molto spesso mi sono imbattuto in argomenti complessi, e a me concettualmente estranei, ma sono riuscito a sviluppare un metodo per analizzare e comprendere anche il più astruso dei concetti.
Lascia che te lo sveli.
Tutto parte da comprendere il perché.
Vedi, un Bloom Filter è un strumento. Come tale deve essere stato inventato da qualcuno per risolvere un problema specifico.
Per cui, capendo il problema saremo noi stessi a pensare che ci voglia una soluzione che abbia determinate caratteristiche. Quelle caratteristiche saranno proprio le fondamenta su cui costruiremo il nostro palazzo di conoscenza.
Il problema
Il Bloom Filter fu inventato nel 1970, da Burton Howard Bloom.
A quel tempo, come potrai facilmente immaginare, la tecnologia dei supporti di archiviazione non permetteva grandi velocità di lettura e scrittura. Gli SSD non esistevano, e il termine Hard Disk era appena stato coniato per differenziare le nuove unità dai Floppy disk.
Oggi ci lamentiamo se un social network impiega qualche secondo a caricare la schermata iniziale. Un tempo 2 minuti di attesa erano velocità pura, anche se molte applicazioni avevano necessità di ridurre i tempi di accesso ai dati.
Questo era soprattutto vero per le ricerche. Devi trovare quel dato in memoria? Mettiti comodo.
Immagina la reazione che avresti se dopo aver aspettato 25 minuti per compiere una ricerca scoprissi che l’elemento non fosse presente in memoria.
Avverti la frustrazione?
Serviva dunque un sistema che permettesse di evitare di compiere ricerche inutili su disco. Qualcosa che ci desse la sicurezza che un dato non fosse presente in memoria, risparmiandoci l’attesa.
Allora facciamo in questo modo: posso crearti una struttura che ti assicuri l’assenza di un dato in memoria, ma devi accettare un compromesso. Alcune volte potrebbe dirti che un dato sia presente quando invece non lo è.
In questo modo ti riduco le ricerche del 33%, a tutto vantaggio del tuo tempo.
Fu così che nacque l’idea di ricorrere a una struttura probabilistica. Ci sono però altri elementi poco chiari: cerchiamo di comprenderli meglio!
Come funziona il Bloom Filter?
Per capire come funzioni il Bloom Filter dobbiamo armarci di alcuni termini. Avremo bisogno di un array di bit, di una funzione di hashing, e di fiducia nella matematica.
Inizializzazione e inserimento dati
Un Bloom Filter vuoto è inizializzato come array di m bit azzerati. Sono poi necessarie k funzioni di hashing, scelte casualmente, ognuna delle quali in grado di mappare un elemento della base dati a una delle m posizioni dell’array. La mappatura deve peraltro avere una distribuzione uniforme.
Presta attenzione a una cosa: il numero delle funzioni di hashing è indipendente dal numero di bit, e dagli elementi dell’insieme, per cui m è diverso da k e da N.
L’aggiunta di un elemento può essere compiuta ricalcolando le k funzioni di hashing ottenendo le k posizioni nell’array, e settando i relativi bit a 1.
Possiamo dire che un Bloom Filter è una struttura dati efficiente perché il tempo richiesto per aggiungere o controllare l’elemento è costante, indipendente dal numero di elementi già presenti, ed è funzione di k. Usando la notazione O grande scriviamo O(k).
Verifica
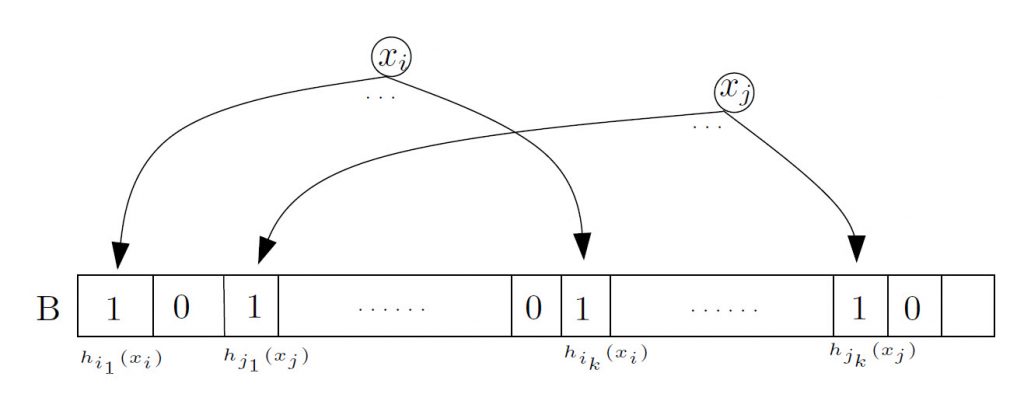
La verifica della presenza di un elemento è compiuta calcolando le funzioni di hashing sull’elemento controllato, determinando quali bit debbano essere validati.
L’elemento è assente nell’insieme se anche uno solo dei bit è 0.
L’elemento potrebbe essere presente nell’insieme qualora invece i bit fossero tutti a 1, situazione determinata dall’inserimento di altri elementi nell’array.
Ecco perché all’aumentare degli elementi inseriti nel Bloom Filter cresce la percentuale di falsi positivi e da dove derivi la certezza dell’assenza di un elemento.
Un ultima cosa.
Non abbiamo ancora risposto al perché non sia possibile rimuovere gli elementi precedentemente inseriti.
Ancora una volta, logica alla mano e procediamo con ordine.
Rimuovere un elemento significherebbe settare i bit determinati dalla funzione di hashing a 0. Il problema è che non abbiamo la certezza che uno o più di quei bit siano stati settati a 1 anche dal risultato della funzione calcolata su altri elementi.
Per cui se avessimo effettivamente due elementi, x e y, con almeno un bit in comune, eliminando x avremo il passaggio di quel bit comune da 1 a 0. Ora però alla verifica della presenza dell’elemento y uno dei bit controllati sarà a 0 e avremo allora un falso negativo. Abbiamo cioè erroneamente detto che un elemento fosse assente.
La necessità di non avere falsi negativi di pone allora un rigido compromesso: non possiamo rimuovere elementi una volta aggiunti, o comprometteremmo l’integrità del Bloom Filter.
Infine, la probabilità di ottenere un falso positivo decrementa all’aumentare di m, la lunghezza del filtro, e aumenta al crescere di N, il numero di elementi.
Ti risparmio la formula perché irrilevante al funzionamento del filtro.
Sappi però che il calcolo di tale probabilità è usato per fissare i valori accettabili dei parametri in funzione dell’applicazione del Bloom Filter.
Applicazioni moderne
Il motivo per cui ho deciso di presentarti questa struttura dati dipende dal nostro percorso di analisi e studio delle Privacy Enhancing Technologies. Un Bloom Filter è inutile con le attuali velocità dei supporti di archiviazione, ma si rivela un strumento valido in applicazioni di Private Set Intersection. Per cui è bene conoscerne il funzionamento.
Per il momento è tutto.
Per aspera, ad astra.
Un caldo abbraccio, Andrea



