Dopo aver condotto l‘indagine preliminare sul dataset, che di fatto potremmo assimilare alla prima parte dell’Exploratory data analysis, passiamo ora ad approfondirne ulteriormente la conoscenza tornando ad effetuare su di esso l’EDA.
Obietttivo
Il nostro obiettivo è quello di prevedere il valore corrispondente alle vendite relative ad un singolo prodotto.
Struttura del dataset
Per prima cosa diamo un’occhiata alla struttura del dataset.
Il dataset di training presenta, come quello di test, 11 features ma ha anche una label. Le varaibili indipendenti sono state analizzate nel precedente post, quindi procediamo con la pulizia dei dati.
Fusione test e train
Dal momento che il nostro intento è quello di prevedere una variabile dipendente, basandoci su valori e relazioni tra variabili indipendenti, ogni modifica che apporteremo al dataset di train dovrà essere ripettuta anche su quello di test.
Per ridurre il lavoro e velocizzare le operazioni, uniamo i due dataset.
Pulizia dei dati: fat_content e visibility

Il report preliminare ha messo in evidenza una ridodanza per la feature “Item_Fat_content”: è arrivato il momento di corregerla.

Infine, ci occupiamo della feature visibility sostituendo il valore zero con la media dei valori. C’è overplotting e ci sono outliers: dobbiamo capire come gestirli.
Esplorazione variazione e covariaizone
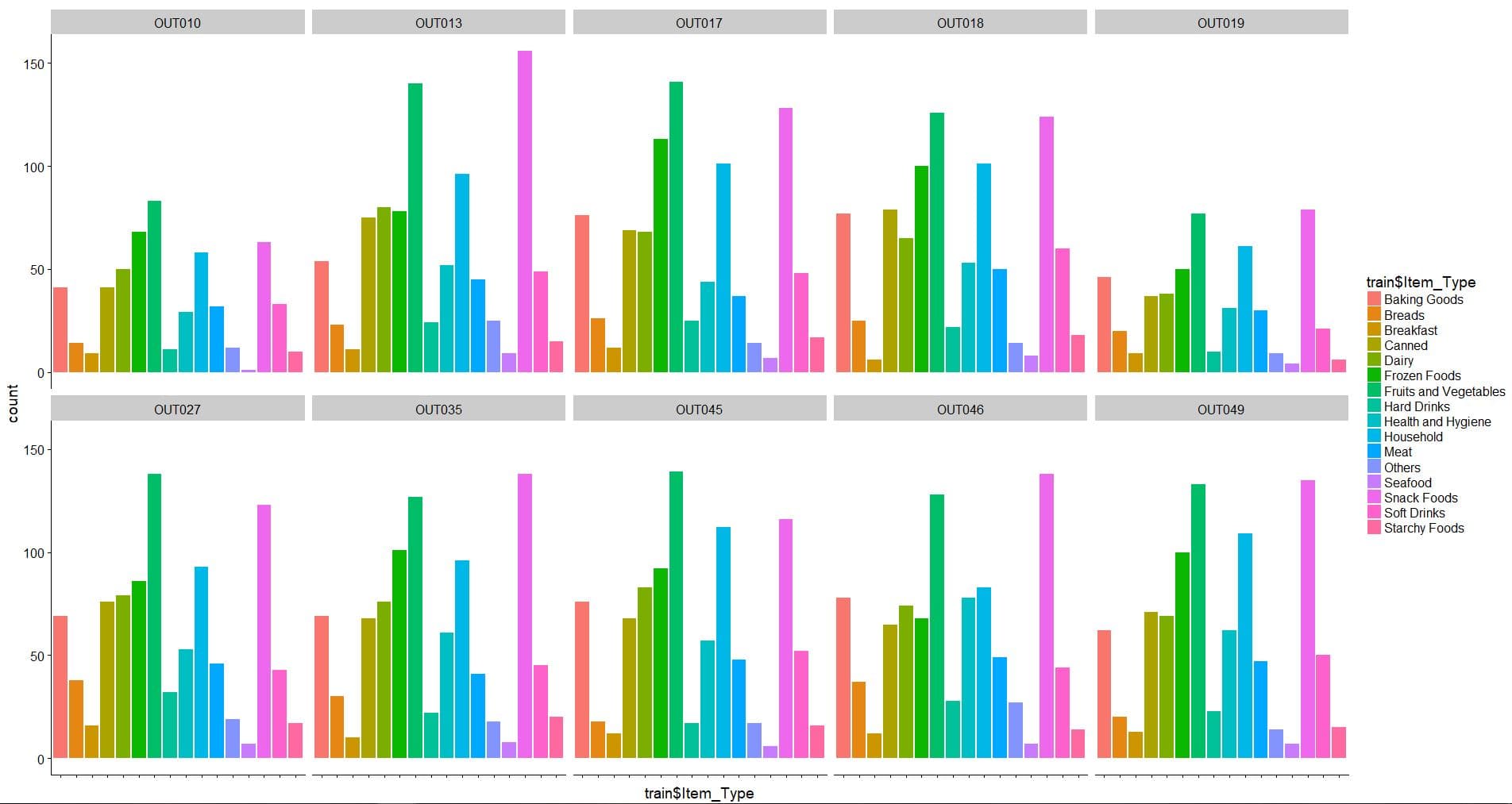
Iniziamo da un dettaglio curioso: OUT027 e le sue vendite fuori scala.
OUT027
Cerchiamo di capire perchél’OUT027 vende così tanto.

E’ un supermarket Type 3 (dato che al momento non sappiamo cosa singifichi) di dimensioni medie, sito in una città di Tier 3: abitanti da 20k a 50k.
Alcune domande:
Quale categoria di prodotti vende maggiormente?
E’ possibile che sia l’unico della città? Possiamo saperlo?
Esiste da tanti anni, quindi gli acquirenti sono fedeli?
Vende prodotti diversi dalle altri filiali?
Espone i prodotti in modo diverso?
Vende prodotti ad un prezzo più conveniente?
Cerhiamo di dare una risposta a queste domande.
Ci ho messo un po’ perché non sapevo come togliere le label del grafico, altrimenti non si vedeva nulla. In R:
theme(axis.text.x=element_blank())
Comunque ho prodotto questo:

Il grafico mostra per ogni filiale il numero di prodotti venduti divisi in base alla loro categoria.
Notiamo a vista che l’OUT027 non mostra alcuna anomalia, anzi se non lo tenessimo d’occhio sarebbe indistinguibile ad un primo sguardo dagli altri.
Invece quello che noto è una strana somiglianza tra le vendite dell’OUT017 e OUT018. Sembrano infatti identiche. Eppure sappiamo che l’OUT017 è di tipo 1 e si trova in una città con 50-100k abitanti, mentre l’OUT018 è di tipo 2 e si trova in una citta con 20-50k abitanti.
Perché due tipologie diverse di negozi, siti in città di dimensioni differenti, vendono la stessa quantità degli stessi prodotti?
Potrebbe avere a che fare con il loro costo?
Potrebbe dipendere dalla loro disposizione all’interno della filiale? (=visibilità)
Perché l’OUT013 (Tipo1) e l’OUT27 (tipo3) e lOUT46 (tipo 1 e Tier 1) vendono così tanta frutta e verdura?
I primi due vendono nella stessa categoria di città (Tier 3): pochi abitani.
In definitiva possiamo concludere che, in riferimento all’OUT027, sappiamo:
“la filiale contraddistinta con l’identificativo OUT027 appartine ad una classe di supermakret senza eguali, nello specifico è di tipo 3, stabilita nel 1985 in una citta di piccole dimensioni (Tier 3). “
Modalità report
Ora modifico un po’ il mio modo di scrivere: lo adatto per fare in modo che il post abbia più l’aspetto di un report.
Modifiche al dataset
Nel tentativo di correggere il dataset, è stata eseguita una pulizia e correzione delle variaibli.
L’ ‘Item_Fat_Content’ presentava una variazione anomala e ridodante. La variabile categoriale assume ora due valori: Low Fat e Regular.
L’ ‘Item_Visibility’ è stato pulito sostituendo il valore di 879 data point che ora presentano un valore mancante (NA)
Prodotti a basso impatto vendite
La vendita di “seafood” è ridotta in ogni filiale, è quindi possibile che queste si trovino lontano da posti di mare o il dataset faccia riferimento ad un periodo invernale con scarsa consumazione di pesce.
Insieme agli “starchy foods” e ai “canned” questi prodotti hanno il minor impatto sulle vendite.
Da valutare una loro momentanea esclusione per alleggerire i grafici.
Prodotti ad alto impatto vendite
I prodotti “Frozen Foods”, “Fruit and Vetables”, “Snack Foods” e “Meat” contribuiscono al maggior numero di vendite.
Contenuto grasso dei prodotti

Dal grafico è evidente che in tutte le filiali si vende un maggior numero di prodotti a basso contenuto grasso. L’OUT019 mostra una differenza di vendite più modesta.
Perché nell’OUT019 la differenza tra i prodotti a basso ed ad alto contenuto grasso è più ridotta?
Visibilità dei prodotti

Il grafico evidenzia Overplotting.
La tendenza mostra come all’aumnetare della visibilità le vendite globali diminuiscano progressivamente. Si evidenzia poi una variazione netta con visibilità superiore a 0.2.
Il fenomeno potrebbe dipendendere dal fatto che oggetti con visibilità maggiore siano in realtà prodotti di peso (e probabilmente dimensioni) superiore. Oggetti non consumabili, che vengono acquistati più raramente.
Problemi del dataset
In questa sezione esploriamo i problemi del dataset.
Mancanze
Nel report preliminare erano emerse incongruenze relative alla visibilità di alcuni prodotti.
Ulteriori analisi hanno appurato la presenza di 526 data points con visibilità pari a 0, poi corretti con valori medi.
Ci sono inoltre 1463 prodotti privi dell’indicatore di peso.
2410 prodotti sono invece privi dell’indicatore di dimensione della filiale. E’ più rilevante tuttavia considerare che solo per tre filiali è effettivamente assente questo dato.
Per il momento è tutto!
Nel prossimo post cercheremo di creare un Report Approfondito sul dataset, rispondendo alle domande che ci siamo fin’ora posti.
Alla prossima!
Un caldo abbraccio, Andrea.



