
Il Bias / Variance Tradeoff è un importante concetto da tenere a mente durante la creazione di un modello di machine learning.
Comprenderlo ci aiuterà non solo a creare modelli più precisi ma anche a evitare d’imbatterci in underfitting e overfitting, due avversari temibili.
L’errore di generalizzazione di un modello (model’s generalization error) può essere espresso come la somma di tre differenti errori:
- Variance
- Bias
- Irreducible Error
Procediamo con ordine.
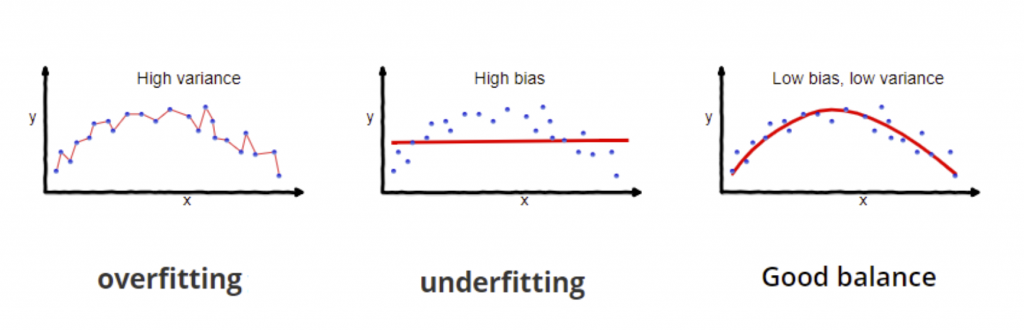
Variance
La Varianza fa riferimento alla sensibilità (sensitivity) del modello alle piccole variazioni nel dataset di training.
Cresce all’aumentare dei gradi di libertà (degrees of freedom).
Ad esempio, è assai probabile che un modello polinomiale di alto grado abbia una high variance e di conseguenza sia prone all’overfitting.
Questo perché l’attenzione posta ai dati di training è eccessiva, e la generalizzazione su quelli mai visti prima pessima.
Come risultato, le performance in allenamento sono ottime e in testing scandalose: overfitting!
Intuitivamente, la variance indica la diffusione dei nostri dati, la loro distribuzione.
Bias
Un termine, tanti signfiicati.
In passato abbiamo trattato il bias all’interno di una rete neurale, e più in generale come parametro di un modello lineare (linear regression).
Qui, ha un significato diverso.
In questo contesto usiamo il termine bias per riferirci all’accuratezza del modello (accuracy), che può essere influenzata dalle assunzioni errate. (wrong assumption)
Pensiamo che i dati abbiano una relazione lineare invece che quadratica? Wrong Assumption.

Con un high bias (scarsa accuratezza) c’è un’alta tendenza all’underfitting, perché l’attenzione posta ai dati di training è minima.
Matematicamente tradotto, il bias assume il valore della differenza tra la previsione media del modello e quello corretto.
Per riassumere:
Irreducible Error
L’Irreducible Error è la terza tipologia di errore a concorrere nella determinazione del Generalization Error.
Il termine è sufficientemente esplicativo.
Banalmente, non può essere ridotto. Perché?

Perché dipende dai dati!
L’Irreducible Errror è infatti legato al rumore (noisiness) presente nei dati. L’unico modo per attenuarne l’effetto, riducendo questa parte dell’errore, è operare:
- Rimuovendo outliers
- Controllando le sorgenti dei dati (sensori mal funzionanti)
Il generalization error sarà quindi definito come:
Generalization Error = Bias*Bias + Variance + Irreducible Error
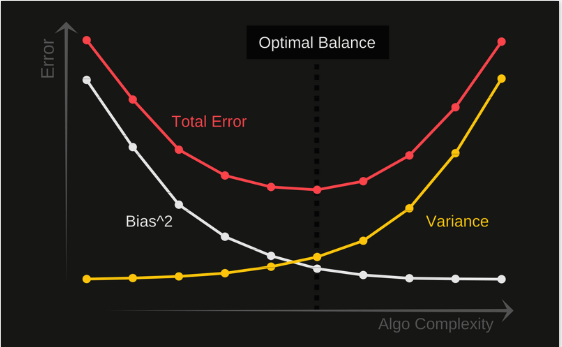
Il Bias / Variance Tradeoff
Probabilmente, avrai già delineato il compromesso che occorre trovare tra le due principali metriche.
All’aumentare della complessità di un modello infatti, la variance crescerà mentre la bias diminuirà (overfitting)
Contrariamente, ridurre la complessità implica un aumento del bias e una diminuzione della variance. (underfitting)
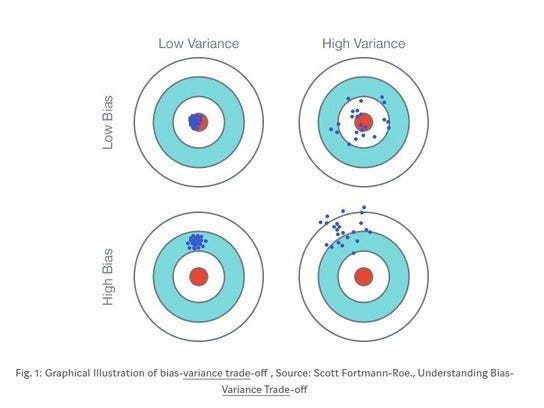
L’equilibrio? Occorre trovare un compromesso…
Un caldo abbraccio, Andrea.



