
Gli autoencoders sono reti neurali artificiali (neural networks) capaci di rappresentare in modo efficiente dati in input imparando i così detti codings, senza supervisione umana.
La mancanza di supervisione, come certamente ricorderai, fa riferimento all’assenza della target feature o label.
I codings costituiscono dunque un’efficiente rappresentazione dei dati, ridotti a una dimensionalità inferiore.
Questo fa degli autoencoders dei potenti strumenti di dimensionality reducton, ma non solo.
Devi infatti sapere che la loro utilità è estendibile a molti altri ambiti.
Quali?
Vediamoli rapidamente!
Possono agire come feature detectors o essere usati per pre-allenare una rete neurale profonda (deep neural network pretraining)
Infine, proprio come coltellini svizzeri dalle mille funzionalità, il loro asso nella manica.
Sono in grado di generare nuovi dati casuali, molto simili a quelli di training, divenendo dunque dei generative models.
Si ecco, non sono proprio come le Generative Adversarial Networks che abbiamo visto qualche giorno fa, anche se riservano grandi sorprese e pertanto sono degne di nota!
Potremmo ad esempio allenare un autoencoder su volti umani e sarebbe in grado di generare nuove facce verosimili.
Sono riuscito a stuzzicare in te la curiosità per questi sistemi?
Ottimo, allora seguimi!
Autoencoders: come funzionano?
Il funzionamento degli autoencoders è relativamente facile.
Imparando a copiare i dati in input per produrre quelli di output.
Ottimo. Finito. Tutti a casa.
Fermo marinaio! Siamo in mezzo all’oceano, dove vuoi andare.
Il compito di un autoencoder potrebbe sembrare banale: non lo è.
Limitando le capacità di apprendimento della rete (vedremo presto perché è necessario farlo) questo compito apparentemente semplice acquista la complessità degna di quell’affascinante mondo che chiamiamo Deep Learning.
Ad esempio, possiamo limitare la dimensione della rappresentazione interna o aggiungere rumore ai dati in input e allenare la rete a ripristinare quelli originali.
Proprio come un professore requisisce gli smartphone prima di un compito scritto per evitare che gli studenti copino, queste limitazioni imposte (constraints) impediscono all’autoencoder di copiare banalmente gli input direttamente sugli ouput, costringendolo a imparare metodi efficienti per rappresentare i dati.
Con l’estremo dono della sintesi nelle mani, i codings costituiscono il sottoprodotto (byproduct) del tentativo compiuto dall’autoencoder di apprendere un’identity function sotto specifiche limitazioni.
Data Representation
Negli anni ’70, William Chase ed Herbert Simon pubblicarono un articolo accademico sulla relazione tra memoria, percezione e pattern matching nel quale presentarono i loro studi sui giocatori di scacchi.
Quelli più esperti sono in grado di memorizzare la disposizione dei pezzi sullo scacchiere in appena 5 secondi, task che molti riterrebbero impossibile.
Come ci riescono?
Ora ti svelo il segreto.
Devi sapere una cosa prima.
Il nostro cervello umano è un sofisticato sistema d’identificazione pattern.
Quando il cervello di un giocatore professionista scruta lo scacchiere, identifica nella disposizione dei pezzi pattern osservati in precedenti partite e rapidamente li memorizza in virtù di tali collegamenti.
Questo significa che una disposizione puramente casuale dei pezzi non permetterebbe al giocatore la medesima velocità mnemonica.
Come i giocatori di scacchi, gli Autoencoders osservano i dati di input, elaborano una rappresentazione efficiente degli stessi producendo degli ouput simili ai dati d’ingresso.
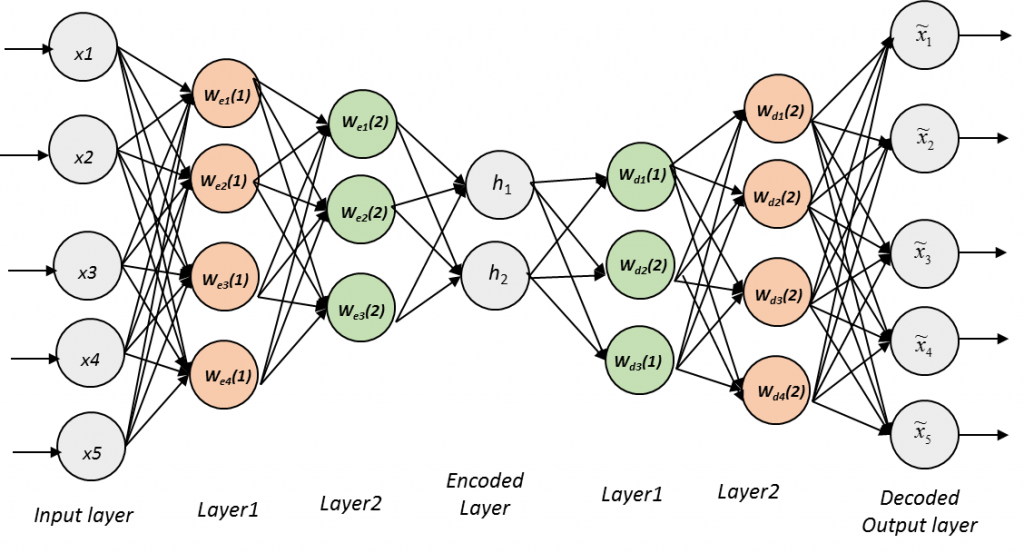
Per far ciò, un autoencoder è sempre costituito da due parti:
- una rete di riconoscimento (recognition network) chiamata encoder che converte gli input nelle rappresentazioni interne.
- un rete generativa (generative network) chiamata decoder che converte la rappresentazione interna in un output.
Talvolta la rappresentazione interna, ovvero lo spazio latente dato dalla compressione dei dati in ingresso, è considerata una componente a sé identificata come code: si tratta del layer tra encoder e decoder.
Ricorda una cosa, prima di passare alla sezione successiva: il numero di neuroni dell’output layer deve essere pari al numero di input.
Infine, sappi che gli output sono spesso chiamati reconstructions poiché gli autoencoders provano a ricostruire gli input mentre la funzione di costo è definita reconstructions loss dal momento che penalizza il modello quando la ricostruzione è differente dall’input.
Autoencoders Training
L’allenamento di un autoencoder richiede che vengano configurati 4 parametri:
- Code size: il numero di nodi nel layer intermedio. Un valore ridotto costituisce una compressione più alta.
- Numero di livelli: un autoencoder può averne diversi, in funzione della complessità dei dati gestiti.
- Numero di nodi di per livello: sovente un autoencoder ha una struttura simmetrica tale per cui i numero di nodi dell’encoder decresce sino al code per poi aumentare nel decoder, con l’ ultimo livello di questo componente uguale per dimensioni a quello del precedente.
- Loss function: la più comune è la mean squared error (mse) o la binary cross entropy, usata quando i valori in ingresso sono nel range [0,1]
L’allenamento ricorre poi all’ausilio dell’algoritmo di backpropagation.
Stacked Autoencoders
Come altre reti neurali anche queste possono avere multipli hidden layer, con una struttura impilata chiamata tecnicamente stacked autoencoders o deep autoencoders.
La presenza di layer aggiuntivi aiuta gli autoencoder a imparare codings complessi.
Al solito però, dobbiamo ricordarci di una cosa fondamentale.
Esiste un compromesso tra complessità ed efficienza, superato il quale arrivano i guai.
Potenziare eccessivamente un autoencoder può rivelarsi controproducente .
Immagina la situazione in cui la rete sia così articolata da imparare un numero arbitrario con il quale mappare ogni dato in input al suo corrispettivo di output.
Ovviamente questo autoencoder non sarebbe bravo a generalizzare su dati mai visti, imparando a memoria quelli in input senza apprendere alcuna rappresentazione utile.
L’architettura di uno stacked autoencoder è generalmente simmetrica rispetto all’hidden layer centrale, il così detto coding layer.
Si, si è un sandwich.
Le domande frequenti sugli Autoencoders
Ho raccolto per te le domande più frequentemente chieste sugli autoencoders. Spero tu le possa trovare utili!
Per il momento è tutto.
Per aspera, ad astra.
Un caldo abbraccio, Andrea



