
Con l’espressione Adversarial AI facciamo riferimento a quell’insieme di tecniche che si pongono l’obiettivo di alterare il comportamento di un modello di machine learning e favorire in qualche modo l’aggressore.
Ho aspettato troppo per questo post. Mea culpa.
Basta indugi.
È finalmente arrivato il momento di analizzare una temibile tecnica: prepararti a esplorare le strategie di attacco avversario, o in altri termini la sfera dell’Adversarial AI.
Prima però, un rapido chiarimento.
Potrebbe sembrare che l’argomento corrente abbia un riferimento alle GAN, le Generative Adversarial Net(work)s che abbiamo esaminato in passato.
Non è così.
Fidati di me: c’è comunque tanto da scoprire!
Adversarial AI
Abbiamo dunque chiarito che per Adversarial AI facciamo riferimento a quelle tecniche con cui un aggressore piega a proprio beneficio l’operato di un modello di machine learning.
Questa spiegazione apparentemente chiara e precisa è invece parecchio nebulosa.
Perché mai un modello di machine learning dovrebbe avere un aggressore?
Perché mai questo fantomatico aggressore dovrebbe voler modificare il comportamento del modello a suo vantaggio?
Soprattutto, come avviene questa modifica, o meglio l’attacco?
Iniziamo la nostra avventura proprio da quest’ultima domanda.
Adversarial Attack
Per produrre il comportamento inaspettato del modello, l’aggressore crea i così detti “adversarial examples” (esempi avversari, benché la traduzione italiana abbia ancora meno senso dell’espressione inglese).
Indistinguibili dagli originali all’occhio umano, gli adversarial examples sono meticolosamente ottimizzati per produrre una previsione errata, ingannando il modello.

Applicando una perturbazione (Adversarial Perturabtion) appositamente studiata a un’immagine, ad esempio quella di un panda, produciamo un adversarial example pressoché inalterato, capace però d’ingannare completamente un modello, producendo peraltro una previsione ad alta accuratezza.
Tipicamente gli aggressori creando questi esempi avversari per tentativi.
Attraverso modifiche continue e ripetute agli input di un modello si studiano gli effetti delle variazioni sulle previsioni fintantoché le alterazioni sommate finiscano per intaccare drasticamente le prestazioni del sistema.
Devi sapere una cosa fondamentale.
Il motivo per cui gli attacchi avversari costituiscano una così pericolosa minaccia è presto detto.
L’aggressore potrebbe infatti sfruttare la vulnerabilità di un particolare comportamento sconosciuto agli sviluppatori a proprio vantaggio.
Esempio
È facile avere una comprensione intuitiva della dimensione della minaccia.
Rifletti un secondo sulle applicazioni odierne dei sistemi di machine learning.
Il settore medico, quello finanziario e della sicurezza, investono parecchio nello sviluppo di sistemi che coadiuvino l’operato umano.
Cosa accadrebbe se la fiducia riposta in questi sistemi fosse tale da affidare loro il nostro futuro, la nostra stessa vita, e ignari di possibili minacce ci facessimo guidare nel baratro?
Considera i seguenti esempi verosimili.
Un licenziamento giustificato da una falsa riduzione di rendimento, identificata da una rete neurale avvelenata (capiremo questi termini più avanti).
Una frode finanziarie compiuta per farsi accettare un prestito da una banca, che sfrutta modelli di machine learning per determinare il rischio di default (in finanza, l’incapacità di un debitore di ripagare le proprie obbligazioni).
Il direttore esecutivo di una nota banca d’investimenti scomparso in un apparente incidente stradale, mentre tornava a casa sulla sua auto a guida autonoma. Il sistema di guida autonoma ha confuso un segnale di STOP per un limite di velocità.
Pensi che stia dando largo sfogo alla mia l’immaginazione?
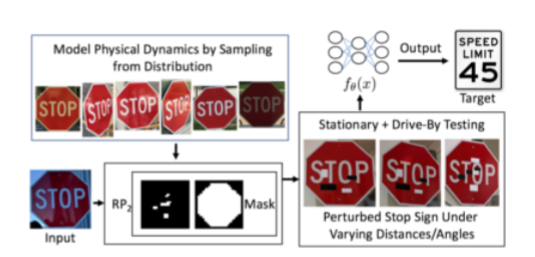
Sappi che un attacco simile è ampiamente documentato in questo articolo accademico.
Spiacente, queste realtà sono più vicine a noi di quanto possiamo anche solo lontanamente immaginare.
Ho stuzzicato il tuo interesse?
In attesa del prossimo post, in cui esploreremo i principali attacchi oggi conosciuti e vedremo le ricerche compiute a riguardo, ti lascio a questo link per maggiori approfondimenti.
Ovviamente esploreremo anche le tecniche per difenderci da questi attacchi.
Un caldo abbraccio, Andrea.



