
Waffle Charts e Word Clouds sono due metodi di rappresentazione dati avanzati che possono fornirci preziosi punti di vista sul nostro dataset: oggi Advanced Data Visualization Python!
Data Visualization Python
Python è un formidabile linguaggio di programmazione capace di semplificare operazioni complesse.
La sua sintesi lessicale unita alla struttura sintattica scarna e ridotta all’osso lo ha reso tra i preferiti in ambito data science e machine learning.
Oggi esaminiamo due metodi di visualizzazione dati in python!
Per Data Visualization si intende quella tecnica che consente di esplorare e rappresentare i dati sotto forma di grafici e rapporti, con l’intento di svilupparne una conoscenza globale.
È buona prassi procedere a visualizzare i dati solo dopo aver diviso il dataset in training e testing. Il nostro cervello è infatti un sofisticato sistema d’individuazione di pattern: così facendo eviteremo di creare pericolosi bias sui dati.
La parte pratica farà uso di un comune dataset canadese che fornisce indicazioni sull’immigrazione dal 1980 al 2013.
Trattandosi di un file xlsx, useremo un metodo di pandas.
Avviamo un jupyter notebook in locale, o su Google Colab, e prepariamoci all’esplorazione importando il dataset:
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
# use the inline backend to generate the plots within the browser
%matplotlib inline
df = pd.read_excel('https://s3-api.us-geo.objectstorage.softlayer.net/cf-courses-data/CognitiveClass/DV0101EN/labs/Data_Files/Canada.xlsx',
sheet_name='Canada by Citizenship',
skiprows=range(20),
skipfooter=2
)
df.head()Con l’ultima funzione di assicuriamo di aver correttamente importato il dataset!
Vediamo adesso il primo Data Visualization Tools in Ptyhon
Waffle Chart
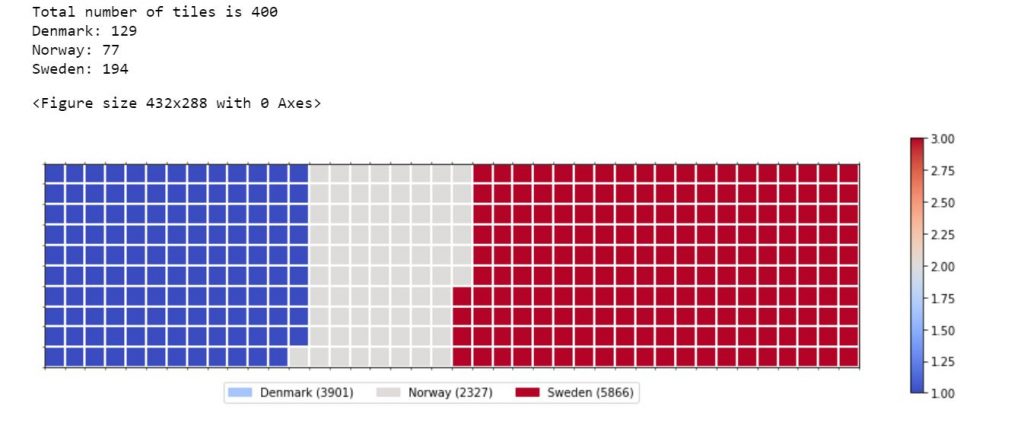
Un Waffle Chart è un efficace grafico per la visualizzazione di un dato in relazione al totale, o per la rappresentazione di un progresso compiuto in funzione di una specifica threshold.
Tradotto in soldoni, visualizzare il progresso verso un obiettivo.
Hai presente i quadratini che compaiono su GitLab o GitHub relativi al numero dei tuoi commit? Waffle Chart!

Matplotlib, una libreria comunemente impiegata per la realizzazione di grafici in ambiente Python, non possiede sistemi rapidi per la creazione di Waffle Chart.
Dobbiamo creare una funzione autonomamente. Ci piace!
Questa è la versione definitiva della funzione: puoi trovare tutti gli step intermedi nel jupyter notebook in allegato!
#libraries needed:
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
import matplotlib.patches as mpatches # needed for waffle Charts
# Step 8: pack everything into a function
def create_waffle_chart(dataset, categories, values, height, width, colormap, value_sign=''):
# compute the proportion of each category with respect to the total
total_values = sum(values)
category_proportions = [(float(value) / total_values) for value in values]
# compute the total number of tiles
total_num_tiles = width * height # total number of tiles
print ('Total number of tiles is', total_num_tiles)
# compute the number of tiles for each catagory
tiles_per_category = [round(proportion * total_num_tiles) for proportion in category_proportions]
# print out number of tiles per category
for i, tiles in enumerate(tiles_per_category):
print (dataset.index.values[i] + ': ' + str(tiles))
# initialize the waffle chart as an empty matrix
waffle_chart = np.zeros((height, width))
# define indices to loop through waffle chart
category_index = 0
tile_index = 0
# populate the waffle chart
for col in range(width):
for row in range(height):
tile_index += 1
# if the number of tiles populated for the current category
# is equal to its corresponding allocated tiles...
if tile_index > sum(tiles_per_category[0:category_index]):
# ...proceed to the next category
category_index += 1
# set the class value to an integer, which increases with class
waffle_chart[row, col] = category_index
# instantiate a new figure object
fig = plt.figure()
# use matshow to display the waffle chart
colormap = plt.cm.coolwarm
plt.matshow(waffle_chart, cmap=colormap)
plt.colorbar()
# get the axis
ax = plt.gca()
# set minor ticks
ax.set_xticks(np.arange(-.5, (width), 1), minor=True)
ax.set_yticks(np.arange(-.5, (height), 1), minor=True)
# add dridlines based on minor ticks
ax.grid(which='minor', color='w', linestyle='-', linewidth=2)
plt.xticks([])
plt.yticks([])
# compute cumulative sum of individual categories to match color schemes between chart and legend
values_cumsum = np.cumsum(values)
total_values = values_cumsum[len(values_cumsum) - 1]
# create legend
legend_handles = []
for i, category in enumerate(categories):
if value_sign == '%':
label_str = category + ' (' + str(values[i]) + value_sign + ')'
else:
label_str = category + ' (' + value_sign + str(values[i]) + ')'
color_val = colormap(float(values_cumsum[i])/total_values)
legend_handles.append(mpatches.Patch(color=color_val, label=label_str))
# add legend to chart
plt.legend(
handles=legend_handles,
loc='lower center',
ncol=len(categories),
bbox_to_anchor=(0., -0.2, 0.95, .1)
)
In alternativa, puoi usare la libreria PyWaffle.
Word Cloud
Certamente una Word cloud è ben più comune di un Waffle Chart. Non è raro trovare Word Cloud in testate giornalistiche o libri di testo.
Sono delle rappresentazioni visive del contenuto di un testo, in cui le parole più frequenti hanno una dimensione , e generalmente un peso (inteso come spessore dei caratteri) maggiore rispetto alle altre.
Anche in questo caso Matplotlib è privo di funzioni o metodi per la creazione di Word Cloud.
Il lavoro della community è qui decisivo. Possiamo usare una libreria di Andreas Mueller per agevolarci il lavoro.
Iniziamo importando le librerie che ci coadiuveranno nel processo di creazione della nuova nuvola:
# import image from PIL import Image from os import path # worcloud from wordcloud import WordCloud
Quindi carichiamo un’immagine stencyl, e procediamo alla creazione della word cloud python con successivo salvataggio in file imagine:
# load the mask
nyc_mask = np.array(Image.open("nyc.jpg"))
# set the worcloud
wordcloud = WordCloud(background_color="white",mask=nyc_mask,contour_width=3, contour_color='steelblue')
# generate it
wordcloud.generate(df['neighbourhood'].to_string())
# store it in a file
wordcloud.to_file("nyc_neighbourhood.jpg")Non ci resta che visualizzare l’immagine appena generata:
# set a proper size
plt.figure(figsize = (14,8))
# show the worcloud
plt.imshow(wordcloud, interpolation='bilinear', aspect='auto')
# hide
plt.axis("off")
plt.show()
Qui, il link al file.
L’articolo è in aggiornamento! Stay Tuned
Un caldo abbraccio, Andrea.



