
Cos’è il Mean-Shift Clustering? Il Mean-Shift Clustering è un algoritmo di raggruppamento a scorrimento di finestra di lettura (sliding-window-based), basato sui centroidi (centroid-based).
Questo post fa parte di una serie sugli algoritmi di Clustering che analizza i 5 migliori algoritmi di clustering. Oltre al Mean-Shift troviamo:
- K-Means Clustering
- DBSCAN
- Expectation–Maximization (EM) Clustering using Gaussian Mixture Models (GMM)
- Agglomerative Hierarchical Clustering
Cerchiamo di capire fin da subito il funzionamento del Mean Shift Clustering!
Lasciami ragionare con te sul significato delle parole.
Sappiamo che, trattandosi di un metodo di clustering, l’obiettivo ultimo è quello di definire dei clusters o grupppi all’interno di un dataset.
Il fatto che venga definito Mean-Shift, significa che dobbiamo aspettarci uno spostamento della media.
Mi spiego meglio.
L’obiettivo è quello d’individuare il punto centrale di ogni gruppo, cluster o classe: è il goal di ogni metodo di clustering, quindi nessuna sorpresa.
Tuttavia è il come questo avvenga a meravigliarci.
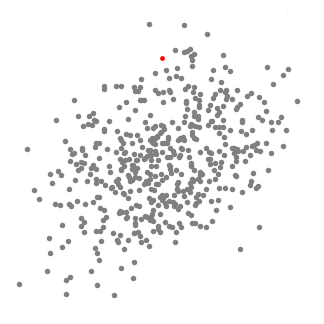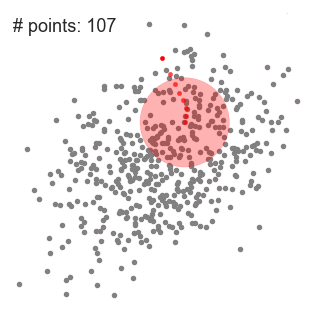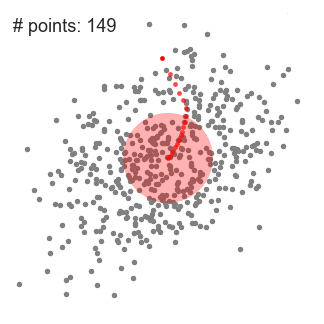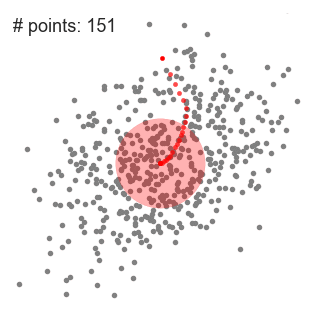
Definiamo la dimensione della finestra di lettura, e prendiamo un punto a caso.
Dapprima procediamo identificando quei punti che costituiscono la media all’interno della finestra.
I candidati sono poi filtrati in una fase successiva eliminando i duplicati vicini, formando così un set finale di punti centrali, associati ai loro rispettivi cluster.
Questo qui sotto è il semplice esempio di funzionamento su un solo cluster:
- L’area rossa è quella che definiamo finestra a scorrimento
- I punti rossi sono i candidati scelti in progressione come centroidi
Come funziona il Mean-Shift Clustering?
Vediamo ora più nello specifico come funziona il Mean-Shift Clustering.
Per farlo, tieni a mente che stiamo considerando uno set di punti in uno spazio bidimensionale come nell’illustrazione precedente.
Potrebbero essere stati generati a partire da un dataset con tecniche di riduzione della dimensionalità, come la PCA.
Il Mean Schift Clustering è un algoritmo di hill climbing, una tecnica di ottimizzazione matematica che appartiene alla famiglia della ricerca locale.
Contrariamente a un algoritmo di Gradient Descent che segue e ricerca la discesa dell’elevazione, quello di Hill Climbing si muove continuamente nella direzione di maggiore elevazione, terminando l’esecuzione al raggiungimento del picco massimo o quando nessun valore più alto è presente.
Come funziona il mean-Shift Clustering? Il Mean-Shift Clustering funziona allora così:
- Definiamo il kernel come una finestra a scorrimento circolare (circular sliding window) centrata in un punto C scelto casualmente (randomly selected) e con raggio R.
- A ogni iterazione, il kernel è mosso verso la regione di più alta densità, ricalcolando il punto medio sulla base di quelli presenti all’interno della finestra. La densità è quindi riferita al numero di osservazioni all’interno del kernel.
- Il processo iterativo termina quando non ci sono più direzioni verso cui muovere il kernel affinché il numero di elementi al suo interno cresca ulteriormente: si è raggiunto il picco.
Il processo da 1 a 3 può essere compiuto con molteplici finestre, finché tutti i punti non cadano in una sola finestra.
I clusters sono quindi calcolati sulla base dell’appartenenza dei singoli punti alle rispettive finestre.
Quando più finestre si sovrappongono, la precedenza è data alla finestra che contiene il maggior numero di elementi.
Ecco una visualizzazione del processo:

Codice in Python
In python la libreria di riferimento è scikit-learn. Il link, questo.
Per il momento è tutto.
Per aspera, ad astra.
Un caldo abbraccio, Andrea



