
Stai per muovere i primi passi con Streamlit, l’app framework versatile per creare eleganti e sofisticate applicazioni in poche ore.
Ho letto la documentazione e riassunto per te i concetti chiave: eviterai di perdere tempo iniziando fin da subito lo sviluppo.
Basta convenevoli.
Scopriamo insieme come configurare un semplice esempio!
Streamlit | TLDR
Ti ricordo che la parola TLDR è acronimo di Too Long Don’t Read, un’espressione usata per allertare il lettore di un contenuto piuttosto lungo e non strettamente essenziale.
Qualora seguissi la filosofia americana del “prima faccio poi imparo”, passa subito alla macro sezione successiva.
Al contrario puoi abbracciare la filosofia europea e comprendere il funzionamento del framework, muovendo i primi passi con Streamlit successivamente.
In tal caso: sarò sintetico!
Iniziamo subito con il capire a cosa serva streamlit.
È un framework open-source che consente il rapido sviluppo di applicazioni in Python, particolarmente utile a Data Scientist e Machine Learnign Engineers per esporre le loro analisi e creazioni.
Utile dunque per creare un ottimo portoflio di progetti per il proprio CV da Data Scientist.
Per intenderci, è la versione sotto steroidi di un jupyter notebook pronto per interfacciarsi con il Web. Il confronto non è da intendersi a livello di prestazioni e potenza di calcolo, che ovviamente dipendono dalla tua macchina (i.e. il tuo computer) bensì a versatilità.
A breve sarà tutto più chiaro.
Iniziamo subito con le prima caratteristiche.
Local Server & Hot Reload
Streamlit gestisce in autonomia un server locale che espone sulla porta 8501 la nostra app: apriamo il browser e come un sito eccola lì!
Questo è il nostro canvas: possiamo disegnare grafici, aggiungere widget, stampare testo e molto altro.
Abbiamo quindi il vantaggio di testare il design della nostra applicazione nonché interagire con essa in tempo reale.
Passiamo alla seconda peculiarità.
Devi sapere una cosa.
Sono uno sviluppatore web javascript.
In passato ho usato diversi framework per velocizzare il mio lavoro, e una delle caratteristiche che più mi colpì fin da subito fu l’hot reload.
Stiamo parlando della possibilità di apportare una modifica al codice e istantaneamente vederne il risultato nel browser.
È sufficiente cliccare sul tasto Always rerun che compare nell’angolo in alto a destra alla prima modifica rilevata, per attivare questa comodissima modalità.
Avvio Applicazione
Ogni app è un file python opportunamente configurato, a breve vedremo come, che può quindi trovarsi sul nostro computer oppure in cloud.
Quindi, sono due le principali casistiche in cui potremmo trovarci:
- Avviare un’app dal un percorso locale
- Avviare un’app da un percorso remoto.
In entrambi i casi, il flow è molto semplice.
Per la prima occorre digitare:
streamlit run your_script.py [-- script args]
Come noti, possiamo passare argomenti addizionali per operare una configurazione all’avvio dell’app.
Qualora ci trovassimo nel secondo scenario descritto, in possesso dell’url remoto del file, per l’avvio dell’app è sufficiente digitare:
streamlit run https://www.remoteurl.com
Per trovare degli esempi già pronti ti esorto a consultare la raccolta Awesome Streamlit, molto utile per imparare tecniche e procedure più complesse osservando applicazioni funzionanti.
Streamlit Data Flow
Scendiamo a un livello più tecnico, studiando come Streamlit gestisce il data flow.
La libertà di creare un’applicazione in semplice Python, senza costrutti complessi, è pagata con l’esecuzione from top to bottom dello script ogni volta che si verifica almeno una delle seguenti condizioni:
- Il codice è modificato (fase di sviluppo)
- L’utente interagisce con i widget dell’app (fase di sviluppo e produzione)
Qualora avessimo previsto delle funzioni particolarmente costose in termini di tempo d’esecuzione, questo potrebbe diventare un problema.
Streamlit ci offre allora una comoda e versatile soluzione: il decoratore @st.cache
Streamlit Caching
La gestione interna della cache ci consente di svolgere operazioni dispendiose, come il fetching dati dal web o il caricamento di pesanti dataset, in modo efficiente.
L’abilitazione della cache per una funzione avviene sfruttando il decoratore @st.cache.
@st.cache # 👈 This function will be cached
def my_slow_function(arg1, arg2):
# Do something really slow in here!
return the_outputWrappando la funzione in questo modo avvisiamo Streamlit di eseguire nuovamente il codice se e solo se identifica un cambiamento ad almeno una delle seguenti parti:
- Il valore di una qualsiasi variabile esterna usata nella funzione
- Il corpo della funzione
- I parametri di input
- Il corpo di una qualsiasi funzione usata all’interno di quella cachata.
Per maggiori dettagli, ti esorto a controllare la documentazione relativa alla cache.
Streamlit Widget
Come anticipato in precedenza, la nostra app è un canvas in cui inserire widget. Possiamo scegliere tra slider, pulsanti, checkbox e molto altro.
import streamlit as st
x = st.slider('x') # 👈 this is a widget
st.write(x, 'squared is', x * x) # let's print the resultUno degli elementi strutturali principali è la Sidebar, con la quale creare un menu laterale in cui disporre pratici widget per settare le configurazioni dell’app.
Ancora una volta, l’organizzazione degli elementi al suo interno è studiata per essere semplice e intuitiva: invece di st.slider basterà un st.sidebar.slider
import streamlit as st
# Add a selectbox to the sidebar:
add_selectbox = st.sidebar.selectbox(
'How would you like to be contacted?',
('Email', 'Home phone', 'Mobile phone')
)
# Add a slider to the sidebar:
add_slider = st.sidebar.slider(
'Select a range of values',
0.0, 100.0, (25.0, 75.0)
)Bada bene che non tutti i widget sono supportati, al momento, dalla sidebar. st.write, st.echo, e st.spinner appartengono a questo gruppo.
Funzionalità aggiuntive
Una delle funzionalità più sorprendenti incluse nel framework è quella di poter registrare lo schermo, con tanto di audio, e condividere il video in formato WebM: LinkedIn, YouTube o una semplice email da inviare al cliente.
Per attivare l’opzione è sufficiente cliccare sulle tre barre orizzontali in alto a destra e selezionare la relativa voce.
Un ripasso veloce
Prima di passare alla parte pratica, un rapido ripasso degli elementi fin’ora analizzati. Per chiudere il cerchio teorico sul funzionamento del framework, possiamo dire che:
- Le App Streamlit sono script in semplice Python eseguiti con approccio top-down: dall’alto al basso.
- Ogni volta che un utente apre una tab del browser che punta all’applicazione lo script viene seguito.
- Durante l’esecuzione dello script, Streamlit stampa il risultato sulla pagina.
- Le funzioni possono fare uso della cache per migliorare le prestazioni
- A ogni interazione con i widget, lo script dell’app è rieseguito.
Iniziamo ora la scrittura del codice vero e proprio.
Primi passi con streamlit
Per muovere i primi passi con streamlit dobbiamo innanzitutto procedere con l’installazione del framework:
pip install streamlit
Procediamo ora a creare la nostra prima app, definendo un file python che chiameremo sreamlitApp.py.
La nostra semplice applicazione farà uso di alcuni widget base sfruttando il meccanismo di cache per massimizzare le prestazioni.
Più nel dettaglio, configureremo una sidebar offrendo all’utente la possibilità di scegliere quale feature mostrare nel grafico, e un selettore per il numero di dati da includere.
"""
A simple eploration app to showcase Streamlit
powerful features
Author: Andrea Provino
"""
import numpy as np
import pandas as pd
import seaborn as sns
import streamlit as st
import time
@st.cache
def load_data(n_rows=1000):
time.sleep(4) # 👈 make our function super slow
dataframe = pd.read_csv('airbnb.csv', nrows=n_rows)
return dataframe
def main():
# App settings
title = st.empty()
# 🔨 define our sidebar title
st.sidebar.title("Options")
# 🔨 define our sidebar subtitle
st.sidebar.subheader("Select feature")
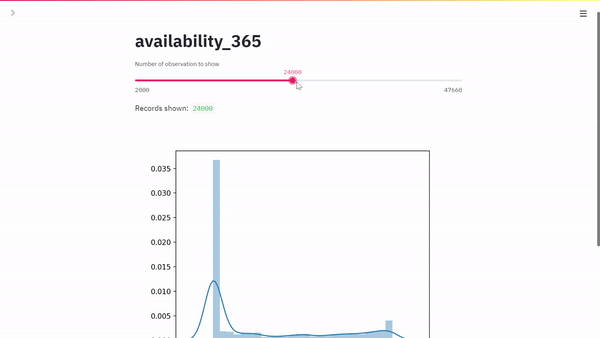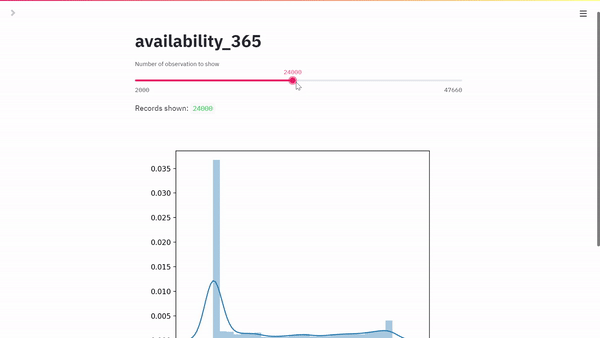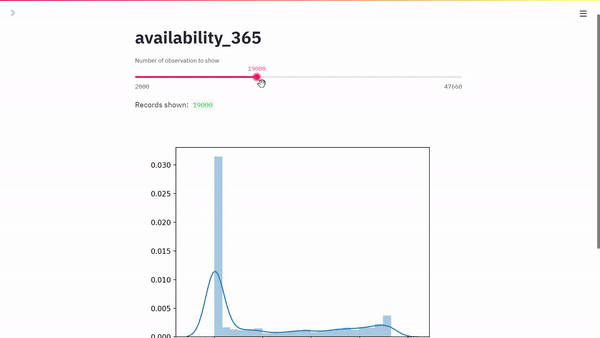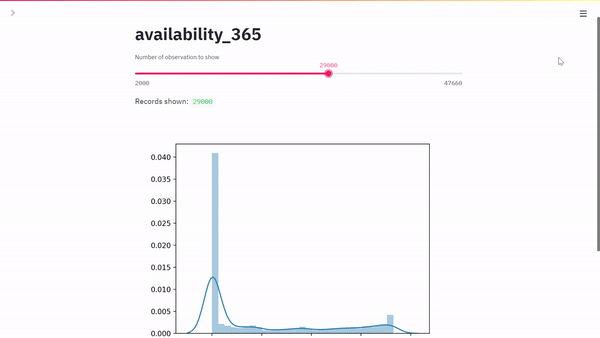
max_rows = st.slider(
"Number of observation to show",
min_value=2000,
max_value=47660, # should be set automatically
value=2000,
step=1000,
)
# our dataset
df = load_data(max_rows)
# show to the user how many records are loaded
st.write("Records shown: ", df.shape[0])
# get a list of all numeric columns
numeric_columns = df.select_dtypes(exclude=object).columns.values
# create a feature picker
feature = st.sidebar.selectbox(
"Click below to select a new feature",
numeric_columns
)
# set a proper title
title.title(feature)
# Canvas
sns.distplot(df[feature])
st.pyplot()
main()
Ecco il nostro risultato:
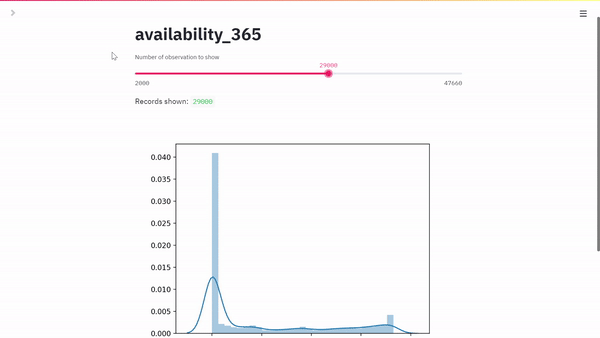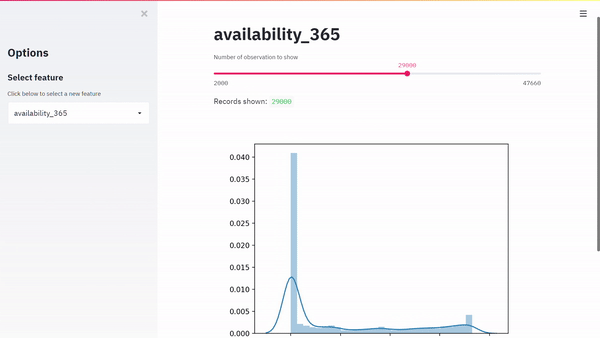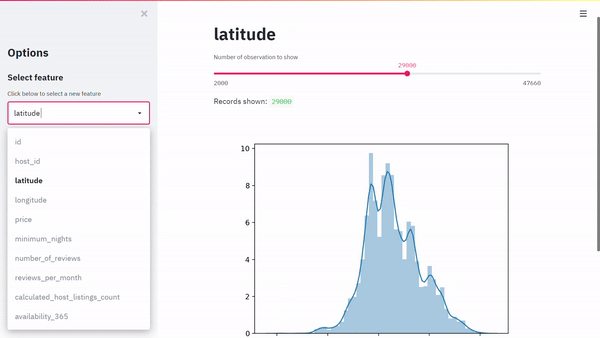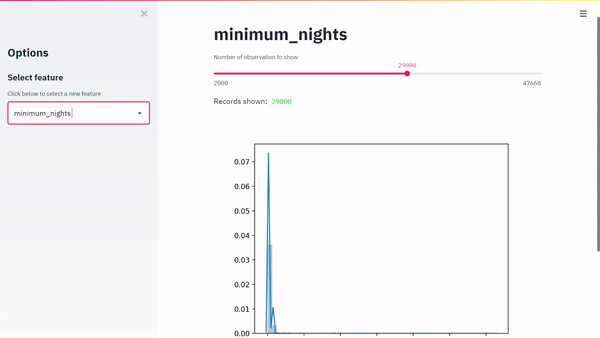
Il codice andrebbe migliorato, me per un post intitolato primi passi con streamlit, direi che può andare bene.
In futuro vedremo come inserire logiche più complesse e mandare live qualcosa che sia realmente utile!
Next?
Sto per svelarti qualcosa di potentissimo.
Abilitando l’opzione gratuita streamlit for teams, possiamo aumentare ulteriormente la facilità di sviluppo nonché quella di rilascio.
Non finisce qui.
Questa operazione ha almeno due vantaggi:
- Iscrizione alla Community Edition Beta, che consente il deployment one-click delle app create
- Iscrizione alla newsletter per ricevere in anteprima i futuri aggiornamenti.
A breve, avremo accesso a enterprise-grade features quali:
- autenticazione
- logging
- auto-scaling
Meglio evitare di perdersele!
Ho riletto le ultime righe: sembra che mi abbiano pagato per farti iscrivere.
Calma, calma.
Non ho venduto il mio entusiasmo!
Fai benissimo a investire risorse altrove, se pensi che la piattaforma non sia all’altezza del tuo tempo.
Per il momento è tutto!
Un caldo abbraccio, Andrea.



