
Una FCN o Fully Convolutional Network è una deep neural network (rete neurale profonda) che supera le limitazioni delle convenzionali CNN eliminando il dense layer in favore di 1×1 convolutional layers.
Abbiamo studiato insieme il funzionamento delle reti CNN, e sappiamo che per quanto avanzate siano sono comunque limitate.
Le Convolutional Neural Networks sono infatti dotate di fully connected layers che bloccano le dimensioni dell’input, costringendo a un ridimensionamento in caso differiscano da quelle consentite.
Eliminando questi livello, superiamo le restrizioni.
Ecco il punto.
L’assenza dei fully connected layers consente alle FCN Networks di:
- elaborare immagini di diverse dimensioni, cosa non possibile con le strutture fisse convenzionali delle CNN.
- avere una struttura più snella (lower parameters) e aumentare quindi la velocità computazionale, riducendo la latenza (low latency).
Siamo così in grado di gestire abilmente immagini con dimensioni non convenzionali di 300 x 30 pixel, per esempio, che avrebbero altrimenti richiesto ridimensionamenti e conseguenti perdite di dati.
FCN Networks for Semantic Segmentation
Quando un’immagine di grandi dimensioni è fornita in ingresso, un FCN produce una feature map e non solo una classe come per un’immagine di dimensioni standard.

La feature map generata è in questo caso una heatmap della classe richiesta.
In altri termini la posizione dell’oggetto interessato è evidenziata dalla heatmap e la FCN può quindi essere facilmente impiegata in un task di image segmentation.
Dobbiamo però porre l’attenzione a una cosa.
Il problema di un mappa così generata riguarda le dimensioni.
I numerosi layer convoluzionali scalano le immagini ricucendone le dimensioni, durante i processi che definiamo di down sampling.
Ecco perché è nel nostro interesse effettuare un processo di up-sampling attraverso una tecnica di interpolazione.
Concedimi una breve digressione sulle tecniche di up-sampling. Ti prometto che sarò breve e conciso.
Up-sampling Techniques
Consideriamo di avere una piccola immagine di 64×64 pixels e trascuriamo lo spazio colore per il momento.
In totale avremo 4096 pixels.
Ora, pensa di voler ingrandire l’immagine affinché risulti essere di 256×256 pixels. Nella nuova immagine conosciamo il valore di 1 pixel ogni 4:
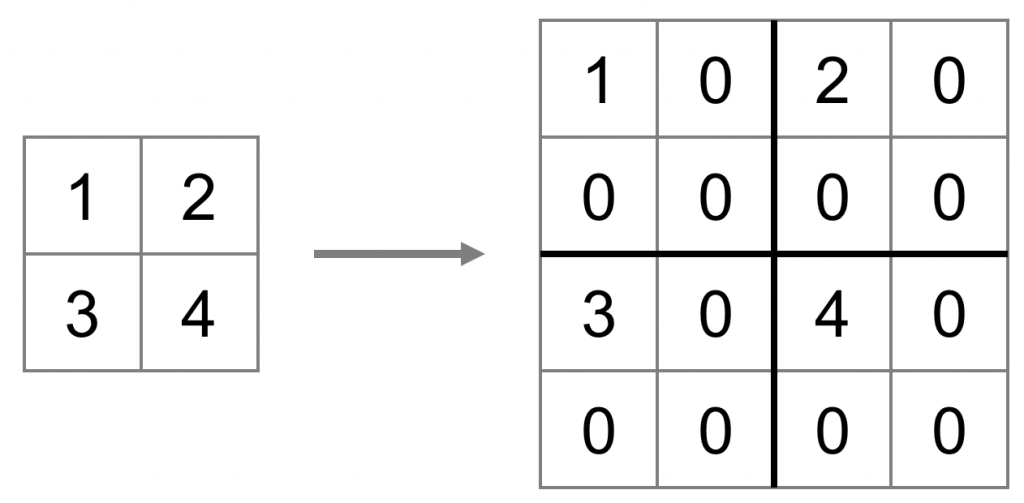
Benissimo!
Come effettuiamo l’up-sampling?
Le più comuni tecniche per effettuare l’up-sampling sono:
- Nearest-Neioghboor: copiare il valore del pixel più vicino
- Up-sampling Bilineare: calcolare il valore dei pixel attraverso l’interpolazione lineare e l’uso dei pixel vicini.
- Up-sampling Bicubico: calcolare il valore dei pixel attraverso l‘interpolazione polinomiale, più complessa a livello computazionale ma dal risultato migliore.
Qui trovi maggiori dettagli.
Nelle FCN Networks tendenzialmente si usano deconvoluzioni capaci di catturare anche relazioni non lineari.
Una deconvoluzione è anche chiamata convoluzione trasposta. Per darti un’idea, ecco una GIF:
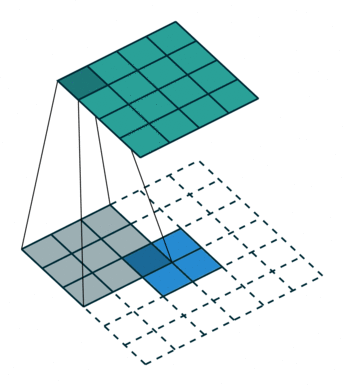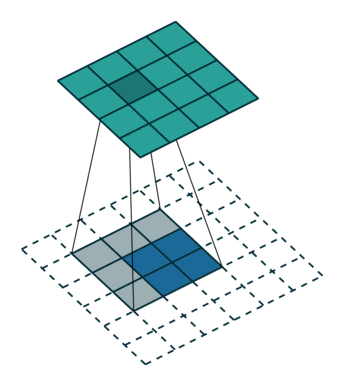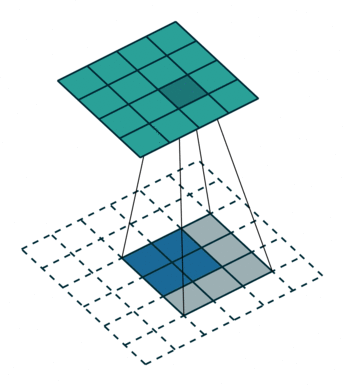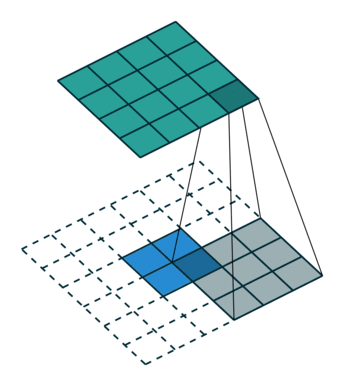
How FCN works? | FCN Networks Architectures
Come funziona una FCN Network? In altri termini, qual è l‘architettura di una FCN Network?
Nell’architettura di una FCN Networks distinguiamo due grandi sezioni:
- Encoder, la parte di Down Sampling
- Decoder, quella di Up Sampling
Questa struttura è comune a molteplici fully convolutional networks.
In un mondo ideale eviteremmo l’impiego dei layer convoluzionali limitandoci ai Pooling Layers, tenendo la stessa dimensione in ogni livello della rete.
Questa tattica è atroce a livello computazionale, dato l’enorme volume di parametri da computare.
Quindi i livelli convoluzionali sono necessari.
Però quanti?
Ecco allora che in base al numero di Convolutional Layers distinguiamo le varie architetture di Fully Convolutional Networks.
FCN-32
L’architettura FCN-32 ha un encoder che riduce l’immagine iniziale di 32 volte, per poi ricostruirla attraverso il decoder che svolge il processo inverso.
In questo flusso, la perdita di informazione è significativa, e l’immagine risultante è poco dettagliata.
Questo perché la rete fa grande fatica nel processo di ricostruzione con i pochissimi dati forniti (i.e. Perché l’immagine originale è stata scalata di un fattore x32)
Per risolvere questo problema, esistono due ulteriori architetture: FCN-16 e FCN-8.
Entrambe adottano un’intelligente strategia.
Anziché fare riferimento alla sola feature map, per la ricostruzione impiegano parte dei livelli di pooling precedentemente appresi.
Questi nuovi particolari livelli si configurano quindi come livelli di deconvoluzione (learned deconvolution layers)
Per il momento è tutto.
Per aspera, ad astra.
Un caldo abbraccio, Andrea



